shl-sbcEmbed-v1 (Speaker Detection)
Version Changelog
| Plugin Version | Change |
|---|---|
| v1.0.0 | Initial plugin release with OLIVE 5.0.0 |
| v1.0.1 | Updated to be compatible with OLIVE 5.1.0 |
| v1.0.2 | Bug fixes, released with OLIVE 5.2.0 |
Description
Speaker Highlighting plugins will detect and label regions of speech in a submitted audio segment by searching for more speech within the audio that resembles the speaker in one or more user-provided 'seed' regions. Unlike Speaker Identification (SID), SHL is capable of handling audio with multiple talkers, as in a telephone conversation, and will provide timestamp region labels to point to the locations where the desired seed speaker is found. Unlike SID and SDD, Speaker Highlighting is not capable of performing any type of 'enrollment', and can only search for more examples of a speaker from within a given audio segment. There is no persistent speaker information retained for future trials, so a new target speaker seed must be supplied each time a new analysis is requested.
Speaker Highlighting is meant to be used as a quick triage tool within a file, often longer files, where finding more or all speech from a given speaker is the goal. This can be done as a front-end for a task such as Speaker Redaction, where you'd like to remove, disguise, or otherwise process sections of a given speaker's voice, or as a 'helper' tool for Speaker Identification or Speaker Detection, to assist in building better speaker enrollment models for those plugins, by quickly finding additional candidate speech to add to an enrollment.
Domains
- micFarfield-v1
- Domain optimized for microphones at various non-close distances from the speaker, designed to deal with natural room reverberation and other artifacts resulting from far-field audio recording.
Inputs
For scoring, an audio buffer or file, in addition to one or more timestamp regions denoting known locations of the speaker of interest.
Outputs
Speaker Highlighting returns a list of regions with an associated score for each region in the audio where the speaker is determined as 'detected'. Regions are represented in seconds. As with SID, scores are log-likelihood ratios where a score of greater than “0” is considered a detection. The SHL plugins are generally calibrated or use dynamic calibration to ensure valid log-likelihood ratios to facilitate detection.
Example output:
/data/audio/file1.wav 8.320 13.110 speaker 0.5348
/data/audio/file1.wav 13.280 29.960 speaker 3.2122
/data/audio/file1.wav 30.350 32.030 speaker 5.5340
Functionality (Traits)
The functions of this plugin are defined by its Traits and implemented API messages. A list of these Traits is below, along with the corresponding API messages for each. Click the message name below to go to additional implementation details below.
- REGION_SCORER – Score all submitted audio, returning labeled regions within the submitted audio, where each region includes a detected speaker of interest and corresponding score for this speaker.
Compatibility
OLIVE 5.1+
Limitations
Known or potential limitations of the plugin are outlined below.
Speaker Information Persistence
Since Speaker Highlighting has no concept of enrollments, no information is retained between different audio analysis queries, and can only search for more of a given speaker within individual audio buffers or files. It can also only search audio for a single speaker at a time, since it assumes that all provided timestamped regions belong to the same speaker. Just as SID and SDD are sensitive to having "good" data provided as enrollment exemplars to perform properly, care must be applied when choosing the timestamp regions of the target speaker to 'seed' the system. If you provide a region that contains speech from multiple speakers, or is too short, or is noisy, or otherwise compromised, the performance of the system will degrade.
Labeling Resolution vs. Processing Speed vs. Detection Accuracy
Region scoring is performed by first identifying speech regions and then processing the resulting speech regions above a certain length (win_sec) with a sliding window. Altering the default parameters for this windowing algorithm will have some impacts and tradeoffs with the plugin's overall performance.
Shortening the window and/or step size will allow the plugin to have a finer resolution when labeling speaker regions, by allowing it to make decisions on a smaller scale.
The tradeoff made by a shorter window size, though, is that the system will have less maximum speech to make its decisions, resulting in a potentially lower speaker labeling accuracy, particularly affecting the rate of missed speech.
A shorter step size will result in more window overlap, and therefore more audio segments that are processed multiple times, causing the processing time of the plugin to increase.
These tradeoffs must be managed with care if changing the parameters from their defaults.
Minimum Speech Duration
The system will only attempt to perform speaker detection on segments of speech that are longer than X seconds (configurable as min_speech, 2 seconds by default).
Comments
Segmentation By Classification
Live, multi-talker conversational speech is a very challenging domain due to its high variability and quantity of speech from many speakers across varying conditions. Rather than exhaustively segment a file to identify pure regions with a single talker (the vast majority of whom are not of actual interest), SBC scans through the file quickly using target speaker embeddings to find regions that are likely to be from a speaker of interest, based on the scores for their enrolled model. The approach consists on a sliding window with x-set steps as described in Figure 1.
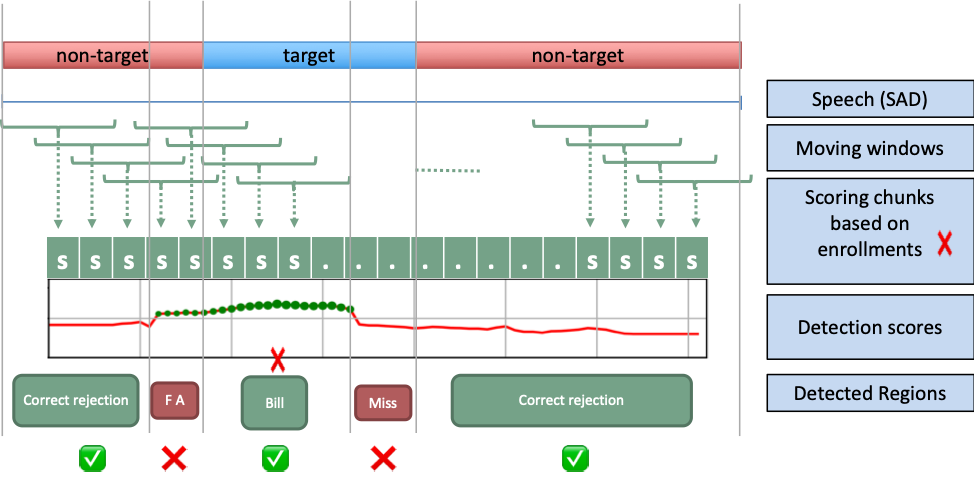 Figure 1: Sliding window approach for Segmentation-by-Classification (SBC) plugin
Figure 1: Sliding window approach for Segmentation-by-Classification (SBC) plugin
The first step this plugin takes is to mask the audio by performing speech activity detection. This allows some natural segmentation by discovering breaks between speech sections caused by silence, and allows the algorithm to focus on the portions of the audio that actually contain speech. Any speech segment longer than X seconds (configurable as min_speech, default 2 seconds) is then processed to determine the likelihood of containing a speaker of interest. Speech regions of up to X seconds (configurable as win_sec, default 4 seconds) are processed and scored whole, while contiguous segments longer than this are then processed using the sliding window algorithm shown above, whose parameters (window size/win_sec and step size/step_sec) are configurable if you find the defaults not to work well with your data type.
Global Options
The following options are available to this plugin, adjustable in the plugin's configuration file; plugin_config.py.
| Option Name | Description | Default | Expected Range |
|---|---|---|---|
| det_threshold | Detection threshold: Higher value results in less detections being output, but of higher reliability. | 0.0 | -10.0 to 10.0 |
| win_sec | Length in seconds of the sliding window used to chunk audio into segments that will be scored by speaker recognition. See below for notes on how this will impact the system's performance. | 4.0 | 2.0 to 8.0 |
| step_sec | Amount of time in seconds the sliding window will shift each time it steps. See below for important notes about the sliding window algorithm behavior. A generally good rule of thumb to follow for setting this parameter is half of the window size. | 2.0 | 1.0 to 4.0 |
| min_speech | The minimum length that a speech segment must contain in order to be scored/analyzed for the presence of enrolled speakers. | 2.0 | 1.0 - 4.0 |
Additional option notes
min_speech
The min_speech parameter determines the minimum amount of contiguous speech in a segment required before OLIVE will analyze it to attempt to detect enrolled speakers. This is limited to contiguous speech since we do not want the system to score audio that may be separated by a substantial amount of non-speech, due to the likelihood of including speech from two distinct talkers. The parameter is a float value in seconds, and is by default set to 2.0 seconds. Any speech segment whose length is shorter than this value will be ignored by the speaker-scoring portion of the plugin.
win_sec and step_sec
The win_sec and step_sec variables determine the length of the window and the step size of the windowing algorithm respectively. Both parameters are represented in seconds. These parameters affect the accuracy, the precision in the boundaries between speakers, and the speed of the approach. Figure 2 shows an example on how the modification of size of the window (W) and the step (S) affect those factors.
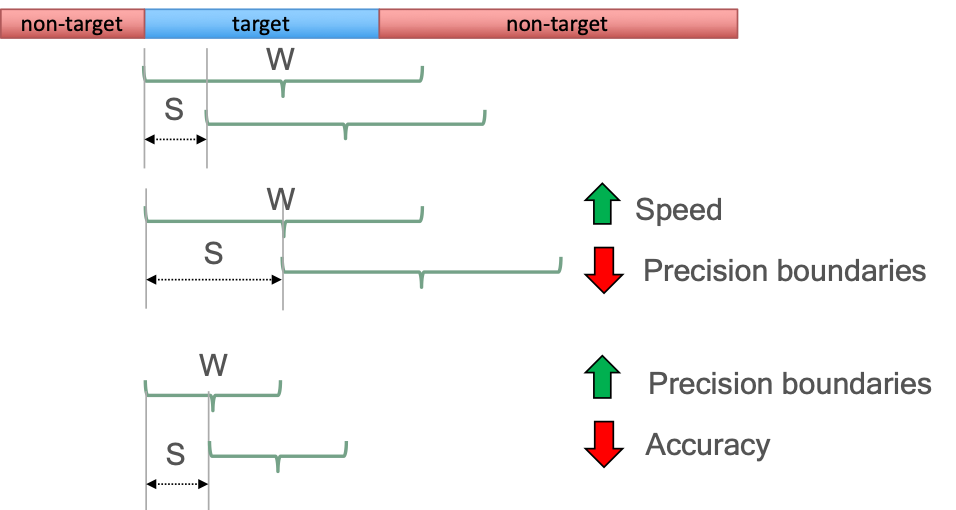 Figure 2: Example of changing the win_sec and step_sec parameters and how this influences the algorithm speed as well as the precision and accuracy of the resulting speaker boundary labels
Figure 2: Example of changing the win_sec and step_sec parameters and how this influences the algorithm speed as well as the precision and accuracy of the resulting speaker boundary labels