OLIVE local LLM configuration options
Introduction
With the release of OLIVE 6.1, the chat interface in the Raven Batch Web GUI as well as certain plugin capabilities are now leveraging large language/vision-language models (LLMs/VLMs) to perform new tasks such as multi-modal summarization. The plugins are configured to use a common local LLM/VLM run as part of the OLIVE server, but can be configured to use other LLMs/VLMs hosted by an OpenAI API compatible LLM server, such as local models hosted using vLLM and Ollama or hosted models such as OpenAI's API or Google's Gemini API.
Chat interface
The chat interface in the Raven Batch Web GUI enables users to perform interactive data analysis of the workflow results. The workflow analysis results are passed transparently to the LLM as part of the chat. This enables asking for questions about the results and transform them using the LLM. Note that this LLM server is running local to the OLIVE server. This means that unless the default/delivered configuration is drastically altered, these results are still staying local; not being passed over the web to an externally hosted model.
Please see the Raven Batch Web GUI documentation for further details.
Currently supported LLM plugins
These plugins currently depend on LLMs for operation (as indicated by -llm in the plugin name):
- sum-txt-llm-commercial-v1.0.0 (Summarization of text inputs)
- sum-img-llm-commercial-v1.0.0 (Summarization of image inputs)
- sum-vid-llm-commercial-v1.0.0 (Summarization of video inputs)
- ner-llm-commercial-v1.0.0 (Named Entity Recognition)
- tpr-llm-commercial-v1.0.0 (Text Punctuation/Capitalization Restoration)
These plugins require an LLM/VLM to operate.
OLIVE local LLM configuration
OLIVE 6.1 integrated LLM/VLM support using llama-server from the llama.cpp project. It supports many local LLMs/VLMs, such as OpenAI's GPT-OSS, Google's Gemma-3, IBM's Granite, and Meta's LLAMA3. The OLIVE server manages the local LLM.
To start the OLIVE server with LLM, use the --llm --gpu parameters. For example, with Martini (Docker) setup:
./martini.sh start --llm --gpu
For further details, please see the Martini (Docker) Setup documentation.
GPU flag MUST also be used:
Note that the --gpu/-gpu flag MUST also be used with this option since there is no CPU-only local LLM support at this time.
Prepared LLM/VLM distributions
We prepared preconfigured LLM/VLM distributions for OLIVE 6.1. They require a compatible NVIDIA GPU, as CPU-only local LLMs are not supported at this time. Please see the GPU Configuration documentation. By default, LLM-enabled OLIVE deliveries ship with cortado, and we optionally have larger models available for users with larger-scale GPU resources available. These are the current options we have:
cortado: Preconfigured distribution of Google's Gemma-3-4B-it-qat-q4_0-gguf. Please review the model license terms before use. This model includes a vision encoder and is capable to support image/video tasks. Uses approx. 5.6GB GPU memory.tall: Preconfigured distribution of Google's Gemma-3-12B-it-qat-q4_0-gguf. Please review the model license terms before use. This model includes a vision encoder and is capable to support image/video tasks. Uses approx. 10.6GB GPU memory.venti: Preconfigured distribution of Google's Gemma-3-27B-it-qat-q4_0-gguf. Please review the model license terms before use. This model includes a vision encoder and is capable to support image/video tasks. Uses approx. 19.5GB GPU memory.
These LLM/VLM distributions must be placed in $OLIVE_APP_DATA/llm.
Local LLM/VLM configuration
If you are receiving an LLM-enabled OLIVE distribution, there should be no configuration changes necessary. Everything should be ready to go out of the box. The following section(s) are for reference or for advanced users.
By default, OLIVE expects a folder named llm in the $OLIVE_APP_DATA folder. This folder contains the main configuration file llm.conf. It is formatted as JSON with key-value pairs containing the LLM configuration. An example configuration is shown below:
{
"--model": "${OLIVE_LLM_DIR}/models/gemma-3-4b-it-q4_0_s.gguf",
"--mmproj": "${OLIVE_LLM_DIR}/models/mmproj-gemma-3-4b-it-f16.gguf",
"--host": "0.0.0.0",
"--port": 5007,
"--ctx-size": 8192,
"--n-gpu-layers": 999,
"-fa": true,
"--cache-type-v": "q4_0",
"--cache-type-k": "q4_0"
}
Below is a table describing these configuration options in detail:
| Option | Explanation |
|---|---|
-m, --model FNAME |
Path to the main LLM file (in GGUF format). |
--mmproj FILE |
Path to a multimodal encoder/projector file (e.g., a vision encoder). The file name typically starts with mmproj-. |
-c, --ctx-size N |
Size of the prompt context (default: 4096, 0 = loaded from model). This defines the maximum amount of text (measured in tokens) or images (for Gemma-3, one image is 256 tokens) that a large language model can process in a single input or conversation. Higher values require a larger amount of GPU memory. We recommend at least 8192. Gemma-3 models support context lenths of up to 128K. |
-ngl, --gpu-layers, --n-gpu-layers N |
Number of layers to store in VRAM. Use a high number (e.g., 999) to store all layers in GPU memory for best performance. |
-fa, --flash-attn |
Enable Flash Attention, a memory-efficient algorithm for attention computation for transformer layers in LLMs. |
-ctk, --cache-type-k TYPE |
Key-value cache data type for storing LLM key vectors for increasing the speed of token generation. This setting enables quantized KV cache, reducing memory usage. Allowed values: f32, f16, bf16, q8_0, q4_0, q4_1, iq4_nl, q5_0, q5_1 |
-ctv, --cache-type-v TYPE |
Key-value cache data type for storing LLM value vectors for increasing the speed of token generation. This setting enables quantized KV cache, reducing memory usage. Allowed values: f32, f16, bf16, q8_0, q4_0, q4_1, iq4_nl, q5_0, q5_1 |
--host HOST |
IP address to listen, or bind to an UNIX socket if the address ends with .sock (default: 127.0.0.1) |
--port PORT |
Port to listen (default: 8080) |
Reference of all local LLM/VLM configuration options
Only advanced users should try to modify the default LLM configuration options
Please consult the OLIVE Support Team if you have questions about changing the default LLM configuration.
Full list of local LLM/VLM configuration options
| Option | Explanation |
|---|---|
-t, --threads N |
number of threads to use during generation (default: -1) (env: LLAMA_ARG_THREADS) |
-tb, --threads-batch N |
number of threads to use during batch and prompt processing (default: same as --threads) |
-C, --cpu-mask M |
CPU affinity mask: arbitrarily long hex. Complements cpu-range (default: "") |
-Cr, --cpu-range lo-hi |
range of CPUs for affinity. Complements --cpu-mask |
--cpu-strict <0\|1> |
use strict CPU placement (default: 0) |
--prio N |
set process/thread priority : low(-1), normal(0), medium(1), high(2), realtime(3) (default: 0) |
--poll <0...100> |
use polling level to wait for work (0 - no polling, default: 50) |
-Cb, --cpu-mask-batch M |
CPU affinity mask: arbitrarily long hex. Complements cpu-range-batch (default: same as --cpu-mask) |
-Crb, --cpu-range-batch lo-hi |
ranges of CPUs for affinity. Complements --cpu-mask-batch |
--cpu-strict-batch <0\|1> |
use strict CPU placement (default: same as --cpu-strict) |
--prio-batch N |
set process/thread priority : 0-normal, 1-medium, 2-high, 3-realtime (default: 0) |
--poll-batch <0\|1> |
use polling to wait for work (default: same as --poll) |
-c, --ctx-size N |
size of the prompt context (default: 4096, 0 = loaded from model) (env: LLAMA_ARG_CTX_SIZE) |
-n, --predict, --n-predict N |
number of tokens to predict (default: -1, -1 = infinity) (env: LLAMA_ARG_N_PREDICT) |
-b, --batch-size N |
logical maximum batch size (default: 2048) (env: LLAMA_ARG_BATCH) |
-ub, --ubatch-size N |
physical maximum batch size (default: 512) (env: LLAMA_ARG_UBATCH) |
--keep N |
number of tokens to keep from the initial prompt (default: 0, -1 = all) |
--swa-full |
use full-size SWA cache (default: false) (more info) (env: LLAMA_ARG_SWA_FULL) |
--kv-unified, -kvu |
use single unified KV buffer for the KV cache of all sequences (default: false) (more info) (env: LLAMA_ARG_KV_SPLIT) |
-fa, --flash-attn |
enable Flash Attention (default: disabled) (env: LLAMA_ARG_FLASH_ATTN) |
--no-perf |
disable internal libllama performance timings (default: false) (env: LLAMA_ARG_NO_PERF) |
-e, --escape |
process escapes sequences (\n, \r, \t, \', \", \) (default: true) |
--no-escape |
do not process escape sequences |
--rope-scaling {none,linear,yarn} |
RoPE frequency scaling method, defaults to linear unless specified by the model (env: LLAMA_ARG_ROPE_SCALING_TYPE) |
--rope-scale N |
RoPE context scaling factor, expands context by a factor of N (env: LLAMA_ARG_ROPE_SCALE) |
--rope-freq-base N |
RoPE base frequency, used by NTK-aware scaling (default: loaded from model) (env: LLAMA_ARG_ROPE_FREQ_BASE) |
--rope-freq-scale N |
RoPE frequency scaling factor, expands context by a factor of 1/N (env: LLAMA_ARG_ROPE_FREQ_SCALE) |
--yarn-orig-ctx N |
YaRN: original context size of model (default: 0 = model training context size) (env: LLAMA_ARG_YARN_ORIG_CTX) |
--yarn-ext-factor N |
YaRN: extrapolation mix factor (default: -1.0, 0.0 = full interpolation) (env: LLAMA_ARG_YARN_EXT_FACTOR) |
--yarn-attn-factor N |
YaRN: scale sqrt(t) or attention magnitude (default: 1.0) (env: LLAMA_ARG_YARN_ATTN_FACTOR) |
--yarn-beta-slow N |
YaRN: high correction dim or alpha (default: 1.0) (env: LLAMA_ARG_YARN_BETA_SLOW) |
--yarn-beta-fast N |
YaRN: low correction dim or beta (default: 32.0) (env: LLAMA_ARG_YARN_BETA_FAST) |
-nkvo, --no-kv-offload |
disable KV offload (env: LLAMA_ARG_NO_KV_OFFLOAD) |
-nr, --no-repack |
disable weight repacking (env: LLAMA_ARG_NO_REPACK) |
-ctk, --cache-type-k TYPE |
KV cache data type for K allowed values: f32, f16, bf16, q8_0, q4_0, q4_1, iq4_nl, q5_0, q5_1 (default: f16) (env: LLAMA_ARG_CACHE_TYPE_K) |
-ctv, --cache-type-v TYPE |
KV cache data type for V allowed values: f32, f16, bf16, q8_0, q4_0, q4_1, iq4_nl, q5_0, q5_1 (default: f16) (env: LLAMA_ARG_CACHE_TYPE_V) |
-dt, --defrag-thold N |
KV cache defragmentation threshold (DEPRECATED) (env: LLAMA_ARG_DEFRAG_THOLD) |
-np, --parallel N |
number of parallel sequences to decode (default: 1) (env: LLAMA_ARG_N_PARALLEL) |
--mlock |
force system to keep model in RAM rather than swapping or compressing (env: LLAMA_ARG_MLOCK) |
--no-mmap |
do not memory-map model (slower load but may reduce pageouts if not using mlock) (env: LLAMA_ARG_NO_MMAP) |
--numa TYPE |
attempt optimizations that help on some NUMA systems - distribute: spread execution evenly over all nodes - isolate: only spawn threads on CPUs on the node that execution started on - numactl: use the CPU map provided by numactl if run without this previously, it is recommended to drop the system page cache before using this see https://github.com/ggml-org/llama.cpp/issues/1437 (env: LLAMA_ARG_NUMA) |
-dev, --device <dev1,dev2,..> |
comma-separated list of devices to use for offloading (none = don't offload) use --list-devices to see a list of available devices (env: LLAMA_ARG_DEVICE) |
--override-tensor, -ot <tensor name pattern>=<buffer type>,... |
override tensor buffer type |
--cpu-moe, -cmoe |
keep all Mixture of Experts (MoE) weights in the CPU (env: LLAMA_ARG_CPU_MOE) |
--n-cpu-moe, -ncmoe N |
keep the Mixture of Experts (MoE) weights of the first N layers in the CPU (env: LLAMA_ARG_N_CPU_MOE) |
-ngl, --gpu-layers, --n-gpu-layers N |
number of layers to store in VRAM (env: LLAMA_ARG_N_GPU_LAYERS) |
-sm, --split-mode {none,layer,row} |
how to split the model across multiple GPUs, one of: - none: use one GPU only - layer (default): split layers and KV across GPUs - row: split rows across GPUs (env: LLAMA_ARG_SPLIT_MODE) |
-ts, --tensor-split N0,N1,N2,... |
fraction of the model to offload to each GPU, comma-separated list of proportions, e.g. 3,1 (env: LLAMA_ARG_TENSOR_SPLIT) |
-mg, --main-gpu INDEX |
the GPU to use for the model (with split-mode = none), or for intermediate results and KV (with split-mode = row) (default: 0) (env: LLAMA_ARG_MAIN_GPU) |
--check-tensors |
check model tensor data for invalid values (default: false) |
--override-kv KEY=TYPE:VALUE |
advanced option to override model metadata by key. may be specified multiple times. types: int, float, bool, str. example: --override-kv tokenizer.ggml.add_bos_token=bool:false |
--no-op-offload |
disable offloading host tensor operations to device (default: false) |
--lora FNAME |
path to LoRA adapter (can be repeated to use multiple adapters) |
--lora-scaled FNAME SCALE |
path to LoRA adapter with user defined scaling (can be repeated to use multiple adapters) |
--control-vector FNAME |
add a control vector note: this argument can be repeated to add multiple control vectors |
--control-vector-scaled FNAME SCALE |
add a control vector with user defined scaling SCALE note: this argument can be repeated to add multiple scaled control vectors |
--control-vector-layer-range START END |
layer range to apply the control vector(s) to, start and end inclusive |
-m, --model FNAME |
model path (env: LLAMA_ARG_MODEL) |
--log-disable |
Log disable |
--log-file FNAME |
Log to file |
--log-colors |
Enable colored logging (env: LLAMA_LOG_COLORS) |
-v, --verbose, --log-verbose |
Set verbosity level to infinity (i.e. log all messages, useful for debugging) |
-lv, --verbosity, --log-verbosity N |
Set the verbosity threshold. Messages with a higher verbosity will be ignored. (env: LLAMA_LOG_VERBOSITY) |
--log-prefix |
Enable prefix in log messages (env: LLAMA_LOG_PREFIX) |
--log-timestamps |
Enable timestamps in log messages (env: LLAMA_LOG_TIMESTAMPS) |
-ctkd, --cache-type-k-draft TYPE |
KV cache data type for K for the draft model allowed values: f32, f16, bf16, q8_0, q4_0, q4_1, iq4_nl, q5_0, q5_1 (default: f16) (env: LLAMA_ARG_CACHE_TYPE_K_DRAFT) |
-ctvd, --cache-type-v-draft TYPE |
KV cache data type for V for the draft model allowed values: f32, f16, bf16, q8_0, q4_0, q4_1, iq4_nl, q5_0, q5_1 (default: f16) (env: LLAMA_ARG_CACHE_TYPE_V_DRAFT) |
--samplers SAMPLERS |
samplers that will be used for generation in the order, separated by ';' (default: penalties;dry;top_n_sigma;top_k;typ_p;top_p;min_p;xtc;temperature) |
-s, --seed SEED |
RNG seed (default: -1, use random seed for -1) |
--sampling-seq, --sampler-seq SEQUENCE |
simplified sequence for samplers that will be used (default: edskypmxt) |
--ignore-eos |
ignore end of stream token and continue generating (implies --logit-bias EOS-inf) |
--temp N |
temperature (default: 0.8) |
--top-k N |
top-k sampling (default: 40, 0 = disabled) |
--top-p N |
top-p sampling (default: 0.9, 1.0 = disabled) |
--min-p N |
min-p sampling (default: 0.1, 0.0 = disabled) |
--top-nsigma N |
top-n-sigma sampling (default: -1.0, -1.0 = disabled) |
--xtc-probability N |
xtc probability (default: 0.0, 0.0 = disabled) |
--xtc-threshold N |
xtc threshold (default: 0.1, 1.0 = disabled) |
--typical N |
locally typical sampling, parameter p (default: 1.0, 1.0 = disabled) |
--repeat-last-n N |
last n tokens to consider for penalize (default: 64, 0 = disabled, -1 = ctx_size) |
--repeat-penalty N |
penalize repeat sequence of tokens (default: 1.0, 1.0 = disabled) |
--presence-penalty N |
repeat alpha presence penalty (default: 0.0, 0.0 = disabled) |
--frequency-penalty N |
repeat alpha frequency penalty (default: 0.0, 0.0 = disabled) |
--dry-multiplier N |
set DRY sampling multiplier (default: 0.0, 0.0 = disabled) |
--dry-base N |
set DRY sampling base value (default: 1.75) |
--dry-allowed-length N |
set allowed length for DRY sampling (default: 2) |
--dry-penalty-last-n N |
set DRY penalty for the last n tokens (default: -1, 0 = disable, -1 = context size) |
--dry-sequence-breaker STRING |
add sequence breaker for DRY sampling, clearing out default breakers ('\n', ':', '"', '*') in the process; use "none" to not use any sequence breakers |
--dynatemp-range N |
dynamic temperature range (default: 0.0, 0.0 = disabled) |
--dynatemp-exp N |
dynamic temperature exponent (default: 1.0) |
--mirostat N |
use Mirostat sampling. Top K, Nucleus and Locally Typical samplers are ignored if used. (default: 0, 0 = disabled, 1 = Mirostat, 2 = Mirostat 2.0) |
--mirostat-lr N |
Mirostat learning rate, parameter eta (default: 0.1) |
--mirostat-ent N |
Mirostat target entropy, parameter tau (default: 5.0) |
-l, --logit-bias TOKEN_ID(+/-)BIAS |
modifies the likelihood of token appearing in the completion, i.e. --logit-bias 15043+1 to increase likelihood of token ' Hello',or --logit-bias 15043-1 to decrease likelihood of token ' Hello' |
--grammar GRAMMAR |
BNF-like grammar to constrain generations (see samples in grammars/ dir) (default: '') |
--grammar-file FNAME |
file to read grammar from |
-j, --json-schema SCHEMA |
JSON schema to constrain generations (https://json-schema.org/), e.g. {} for any JSON objectFor schemas w/ external $refs, use --grammar + example/json_schema_to_grammar.py instead |
-jf, --json-schema-file FILE |
File containing a JSON schema to constrain generations (https://json-schema.org/), e.g. {} for any JSON objectFor schemas w/ external $refs, use --grammar + example/json_schema_to_grammar.py instead |
--swa-checkpoints N |
max number of SWA checkpoints per slot to create (default: 3) (more info) (env: LLAMA_ARG_SWA_CHECKPOINTS) |
--no-context-shift |
disables context shift on infinite text generation (default: enabled) (env: LLAMA_ARG_NO_CONTEXT_SHIFT) |
--context-shift |
enables context shift on infinite text generation (default: disabled) (env: LLAMA_ARG_CONTEXT_SHIFT) |
-r, --reverse-prompt PROMPT |
halt generation at PROMPT, return control in interactive mode |
-sp, --special |
special tokens output enabled (default: false) |
--no-warmup |
skip warming up the model with an empty run |
--spm-infill |
use Suffix/Prefix/Middle pattern for infill (instead of Prefix/Suffix/Middle) as some models prefer this. (default: disabled) |
--pooling {none,mean,cls,last,rank} |
pooling type for embeddings, use model default if unspecified (env: LLAMA_ARG_POOLING) |
-cb, --cont-batching |
enable continuous batching (a.k.a dynamic batching) (default: enabled) (env: LLAMA_ARG_CONT_BATCHING) |
-nocb, --no-cont-batching |
disable continuous batching (env: LLAMA_ARG_NO_CONT_BATCHING) |
--mmproj FILE |
path to a multimodal projector file. see tools/mtmd/README.md note: if -hf is used, this argument can be omitted (env: LLAMA_ARG_MMPROJ) |
--no-mmproj |
explicitly disable multimodal projector, useful when using -hf (env: LLAMA_ARG_NO_MMPROJ) |
--no-mmproj-offload |
do not offload multimodal projector to GPU (env: LLAMA_ARG_NO_MMPROJ_OFFLOAD) |
--override-tensor-draft, -otd <tensor name pattern>=<buffer type>,... |
override tensor buffer type for draft model |
--cpu-moe-draft, -cmoed |
keep all Mixture of Experts (MoE) weights in the CPU for the draft model (env: LLAMA_ARG_CPU_MOE_DRAFT) |
--n-cpu-moe-draft, -ncmoed N |
keep the Mixture of Experts (MoE) weights of the first N layers in the CPU for the draft model (env: LLAMA_ARG_N_CPU_MOE_DRAFT) |
-a, --alias STRING |
set alias for model name (to be used by REST API) (env: LLAMA_ARG_ALIAS) |
--host HOST |
ip address to listen, or bind to an UNIX socket if the address ends with .sock (default: 127.0.0.1) (env: LLAMA_ARG_HOST) |
--port PORT |
port to listen (default: 8080) (env: LLAMA_ARG_PORT) |
--path PATH |
path to serve static files from (default: ) (env: LLAMA_ARG_STATIC_PATH) |
--api-prefix PREFIX |
prefix path the server serves from, without the trailing slash (default: ) (env: LLAMA_ARG_API_PREFIX) |
--no-webui |
Disable the Web UI (default: enabled) (env: LLAMA_ARG_NO_WEBUI) |
--api-key KEY |
API key to use for authentication (default: none) (env: LLAMA_API_KEY) |
--api-key-file FNAME |
path to file containing API keys (default: none) |
--ssl-key-file FNAME |
path to file a PEM-encoded SSL private key (env: LLAMA_ARG_SSL_KEY_FILE) |
--ssl-cert-file FNAME |
path to file a PEM-encoded SSL certificate (env: LLAMA_ARG_SSL_CERT_FILE) |
--chat-template-kwargs STRING |
sets additional params for the json template parser (env: LLAMA_CHAT_TEMPLATE_KWARGS) |
-to, --timeout N |
server read/write timeout in seconds (default: 600) (env: LLAMA_ARG_TIMEOUT) |
--threads-http N |
number of threads used to process HTTP requests (default: -1) (env: LLAMA_ARG_THREADS_HTTP) |
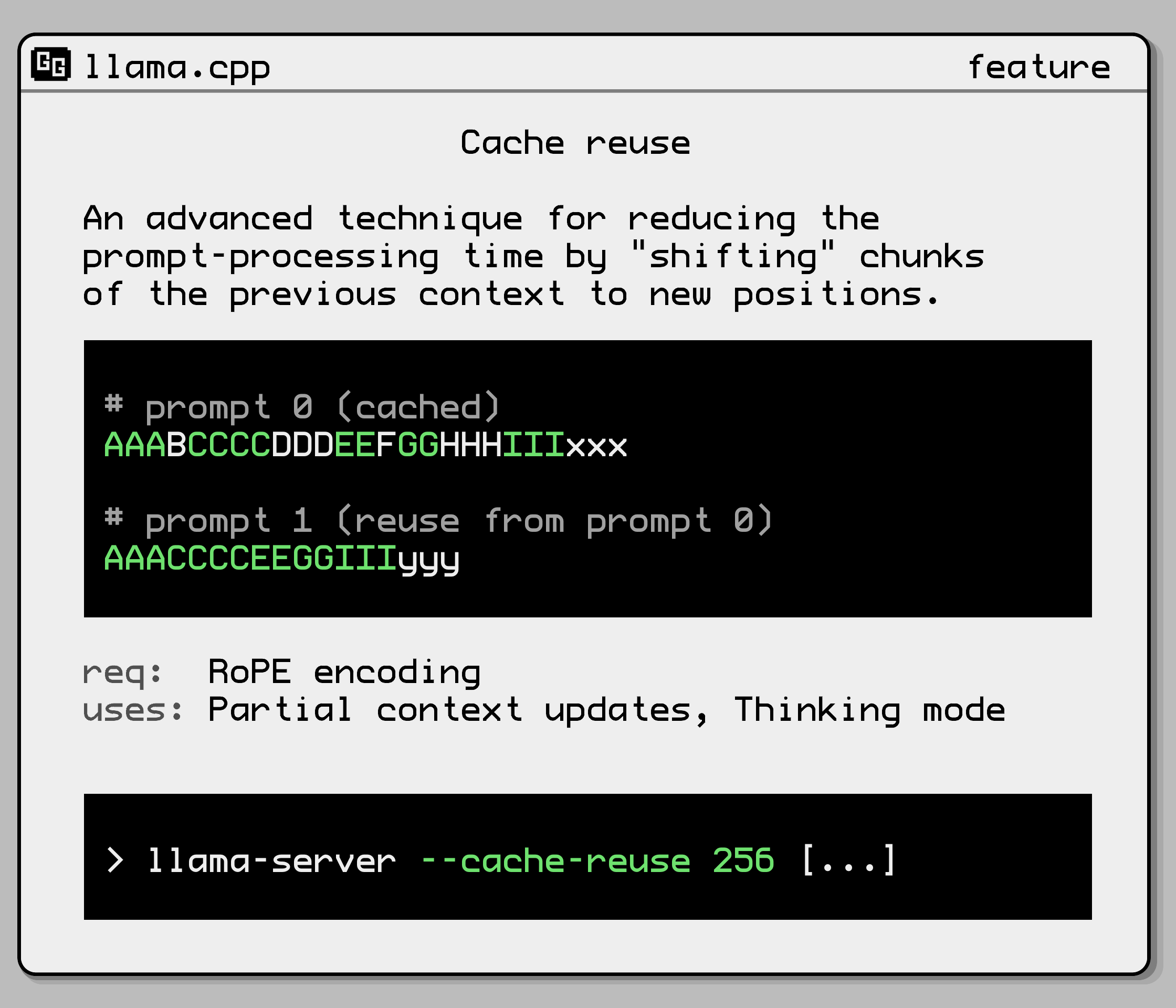
--cache-reuse N |
min chunk size to attempt reusing from the cache via KV shifting (default: 0) (card) (env: LLAMA_ARG_CACHE_REUSE) |
--metrics |
enable prometheus compatible metrics endpoint (default: disabled) (env: LLAMA_ARG_ENDPOINT_METRICS) |
--slots |
enable slots monitoring endpoint (default: enabled) (env: LLAMA_ARG_ENDPOINT_SLOTS) |
--no-slots |
disables slots monitoring endpoint (env: LLAMA_ARG_NO_ENDPOINT_SLOTS) |
--slot-save-path PATH |
path to save slot kv cache (default: disabled) |
--jinja |
use jinja template for chat (default: disabled) (env: LLAMA_ARG_JINJA) |
--reasoning-format FORMAT |
controls whether thought tags are allowed and/or extracted from the response, and in which format they're returned; one of: - none: leaves thoughts unparsed in message.content- deepseek: puts thoughts in message.reasoning_content (except in streaming mode, which behaves as none)(default: auto) (env: LLAMA_ARG_THINK) |
--reasoning-budget N |
controls the amount of thinking allowed; currently only one of: -1 for unrestricted thinking budget, or 0 to disable thinking (default: -1) (env: LLAMA_ARG_THINK_BUDGET) |
--chat-template JINJA_TEMPLATE |
set custom jinja chat template (default: template taken from model's metadata) if suffix/prefix are specified, template will be disabled only commonly used templates are accepted (unless --jinja is set before this flag): list of built-in templates: bailing, chatglm3, chatglm4, chatml, command-r, deepseek, deepseek2, deepseek3, exaone3, exaone4, falcon3, gemma, gigachat, glmedge, gpt-oss, granite, hunyuan-dense, hunyuan-moe, kimi-k2, llama2, llama2-sys, llama2-sys-bos, llama2-sys-strip, llama3, llama4, megrez, minicpm, mistral-v1, mistral-v3, mistral-v3-tekken, mistral-v7, mistral-v7-tekken, monarch, openchat, orion, phi3, phi4, rwkv-world, seed_oss, smolvlm, vicuna, vicuna-orca, yandex, zephyr (env: LLAMA_ARG_CHAT_TEMPLATE) |
--chat-template-file JINJA_TEMPLATE_FILE |
set custom jinja chat template file (default: template taken from model's metadata) if suffix/prefix are specified, template will be disabled only commonly used templates are accepted (unless --jinja is set before this flag): list of built-in templates: bailing, chatglm3, chatglm4, chatml, command-r, deepseek, deepseek2, deepseek3, exaone3, exaone4, falcon3, gemma, gigachat, glmedge, gpt-oss, granite, hunyuan-dense, hunyuan-moe, kimi-k2, llama2, llama2-sys, llama2-sys-bos, llama2-sys-strip, llama3, llama4, megrez, minicpm, mistral-v1, mistral-v3, mistral-v3-tekken, mistral-v7, mistral-v7-tekken, monarch, openchat, orion, phi3, phi4, rwkv-world, seed_oss, smolvlm, vicuna, vicuna-orca, yandex, zephyr (env: LLAMA_ARG_CHAT_TEMPLATE_FILE) |
--no-prefill-assistant |
whether to prefill the assistant's response if the last message is an assistant message (default: prefill enabled) when this flag is set, if the last message is an assistant message then it will be treated as a full message and not prefilled (env: LLAMA_ARG_NO_PREFILL_ASSISTANT) |
-sps, --slot-prompt-similarity SIMILARITY |
how much the prompt of a request must match the prompt of a slot in order to use that slot (default: 0.50, 0.0 = disabled) |
--lora-init-without-apply |
load LoRA adapters without applying them (apply later via POST /lora-adapters) (default: disabled) |
-td, --threads-draft N |
number of threads to use during generation (default: same as --threads) |
-tbd, --threads-batch-draft N |
number of threads to use during batch and prompt processing (default: same as --threads-draft) |
--draft-max, --draft, --draft-n N |
number of tokens to draft for speculative decoding (default: 16) (env: LLAMA_ARG_DRAFT_MAX) |
--draft-min, --draft-n-min N |
minimum number of draft tokens to use for speculative decoding (default: 0) (env: LLAMA_ARG_DRAFT_MIN) |
--draft-p-min P |
minimum speculative decoding probability (greedy) (default: 0.8) (env: LLAMA_ARG_DRAFT_P_MIN) |
-cd, --ctx-size-draft N |
size of the prompt context for the draft model (default: 0, 0 = loaded from model) (env: LLAMA_ARG_CTX_SIZE_DRAFT) |
-devd, --device-draft <dev1,dev2,..> |
comma-separated list of devices to use for offloading the draft model (none = don't offload) use --list-devices to see a list of available devices |
-ngld, --gpu-layers-draft, --n-gpu-layers-draft N |
number of layers to store in VRAM for the draft model (env: LLAMA_ARG_N_GPU_LAYERS_DRAFT) |
-md, --model-draft FNAME |
draft model for speculative decoding (default: unused) (env: LLAMA_ARG_MODEL_DRAFT) |
--spec-replace TARGET DRAFT |
translate the string in TARGET into DRAFT if the draft model and main model are not compatible |
{kind=link}
LLM plugin configuration
With the integration of LLM support in OLIVE 6.1, several plugins using LLM capabilities were added that share a number of global configuration options. These are described below:
The following region scoring options are available to this plugin, adjustable in the plugin's configuration file; plugin_config.py.
| Option Name | Description | Default |
|---|---|---|
| llm_base_url | LLM base URL of an OpenAI API compatible LLM server (such as llama-server, vLLM, or hosted LLMs such as OpenAI). | http://127.0.0.1:5007/v1 |
| api_key | API key/token to use for the LLM server, if required. | token |