OLIVE Python Workflow API
Introduction
The OLIVE Workflow API extends the OLIVE Enterprise API to simplify working with an OLIVE server, allowing clients to request multiple OLIVE tasks with one API call. This eliminates the more verbose and complex calls necessary when using the Enterprise API. In particular, this framework will encapsulate 'feeding' functionality, to link together tasks, like speech activity detection and a plugin that uses speech regions or frames in its processing, or to 'bundle' multiple requests in a single call, rather than having every API call to a plugin be a separate action. The Workflow API is based around binary or text "Workflow Definition" files that SRI distributes to clients. These files contain a 'recipe' to be executed on an OLIVE server to perform analysis, enrollment, and eventually adaption using one or more audio files/inputs. This places the work of specifying how to execute a complex task to execute within the OLIVE server, instead of the client.
To use this API, a client submits the SRI provided Workflow Definition file to an OLIVE server. The server verifies it can run the Workflow Definition through a process called "actualization". If successful, an activated Workflow is returned to the client. This activated Workflow is then ready for one or more analysis (or enrollment) requests. These requests can be made numerous times with one or more audio submissions.
OLIVE still supports the original OLIVE Enterprise API that was based on creating and sending Google Protocol Buffers (Protobuf) message for each request, so if desired, clients can combine classic OLIVE API calls with the Workflow API to implement advanced functionality.
For advanced users, see Creating a Workflow Definition for information on composing your own Workflow Definition files.
For advanced users, see Creating a Workflow Definition for information on composing your own Workflow Definition files.
For more information about working with OLIVE, please see:
Useful Concepts to Know
- Workflow Definition - distributed as a file (text or binary) with these characteristics:
- Similar to Plugins, Workflows are independent of the OLIVE software and can be updated and/or distributed outside of an OLIVE software release.
- Can be submitted to multiple OLIVE servers for actualization in parallel, where actualization is the process of verifying that the server can perform the activities defined in a Workflow Definition.
- Each actualized Workflow is considered unique to the server where it was actualized, as it is possible the plugin/domain names could vary by each server that actualizes the same WorkflowDefinition
- Most Workflow Definitions are implemented with the specific names of plugins/domains delivered with the OLIVE system. Changing the name of a plugin or domain will cause workflows that use them to cease to function.
- Order: a set one or more jobs. There are 3 supported Workflow orders: analysis, enrollment, and unenrollment. Analysis orders require at least one data (audio) input, enrollment orders require one or more data (audio) inputs, plus a class ID, unenrollment inputs do not accept data, only a class ID.
- Job: A set of tasks, plus depending on the order (analysis, enrollment, unenrollment) may include audio (data) and/or as class ID.
- An analysis order typically only includes one job, with that job accepting one audio input.
- An enrollment order may have multiple jobs, where each jobs has it's own set of tasks, one or more data/audio(s), and a class id (i.e. speaker name). Only tasks that support the Class Enroller trait such as speaker enrollment for SID and language enrollment for LID can be part of an enrollment job. Each enrollment job should support enrollment for a single class enroller. This allows enrollments (such as for LID and SID) to be handled separately, since it is very unlikely the same audio and class id (speaker name/language name) would be used for both tasks.
- Unenrollment jobs are similar to enrollment jobs, except that do NOT consume audio/data. They only accept a class ID
- Tasks: at the lowest level, a Workflow is composed of one or more tasks, such as SAD, LID, SID, QBE, ASR, etc. A task typically maps to a traditional plugin/domain, but as we expand the capabilities of the Workflow API, 'tasks' are likely to include functionality that is not implemented by a traditional OLIVE plugin, but by private, helper, components that assist other tasks in the workflow but do not return values to the user.
Limitations
The Workflow API is a new OLIVE extension whose interfaces are subject to change. This release covers two types of behavior:
- bundling of disparate tasks together into a single call and
- restricted feeding processes, wherein the output of one plugin may be fed into one or more other "downstream" plugins that will use this information in their processing. The most common example in this is SAD feeding other processes. The plugins that receive output from other plugins in a workflow must have an interface that accepts this input. I.e. to use SAD output the plugin must be designed to accept SAD input in addition to the usual audio inputs. Current workflows only allow for categorical feeding (e.g. SAD output always goes to SID input) but not conditional feeding behavior (audio goes to the ASR English domain if LID detects file is English).
The most common example in this is SAD feeding other processes. The plugins that receive output from other plugins in a workflow must have an interface that accepts this input. I.e. to use SAD output the downstream plugin(s) must be designed to accept SAD input in addition to the usual audio inputs. Current workflows only allow for categorical feeding (e.g. SAD output always goes to SID input) but not conditional feeding behavior (audio goes to the ASR English domain if LID detects file is English).
Further, the current implementation of workflows does not support tasks that create entirely new domains, like adaptation. This is much easier to accomplish with a direct call to the plugin, as bundling and feeding behavior is not relevant to this activity.
Python Client Install
The OLIVE Python API is distributed as a Python wheel package.
To install, navigate into the 'api' folder distributed with your OLIVE delivery, and install it using your native pip3:
$ pip3 install olivepy-5.3.0-py3-none-any.whl
Or if installing on CentOS, the wheel package includes all 3rd party dependencies, so OlivePy can be installed on a standalone (no Internet) system:
pip3 install -r requirements.txt --use-wheel --no-index --find-links wheelhouse olivepy-5.3.0-py3-none-any.whl
This installs OLIVE and its dependencies into your local Python distribution.
The client source is also available in the olivepy-5.2.0.tar.gz package. OLIVE client dependencies include:
- protobuf
- soundfile (suggested)
- numpy
- zmq
- python3
Integration
Analysis Request
With a Workflow Definition file, it only takes a few steps to make an analysis request. In the following example, a Workflow Definition file (sad_lid_sid.workflow) that supports SAD, LID, and SID analysis is used to make a request:
>>> import olivepy.api.olive_async_client as oc
>>> import olivepy.api.workflow as ow
>>> from olivepy.messaging.msgutil import InputTransferType
>>> import os
>>> client = oc.AsyncOliveClient("example client")
>>> client.connect()
>>> owd = ow.OliveWorkflowDefinition("~/olive/sad_lid_sid.workflow")
>>> workflow = owd.create_workflow(client)
# Send audio as a serialzied buffer
>>> buffer = workflow.package_audio('~/olive/sad_smoke.wav', InputTransferType.SERIALIZED, label=os.path.basename('sad_smoke.wav'))
>>> response = workflow.analyze([buffer])
The analysis response can be pretty printed as JSON:
>>> print("Workflow Results: {}".format(response.to_json(indent=1)))
Workflow Results: [
{
"job_name": "SAD, LID, and SID workflow",
"data": [
{
"data_id": "sad_smoke.wav",
"msg_type": "PREPROCESSED_AUDIO_RESULT",
"mode": "MONO",
"merged": false,
"sample_rate": 8000,
"duration_seconds": 27.9325,
"number_channels": 1,
"label": "sad_smoke.wav",
"id": "ebc1dfa7502841216526768a3f94b095b9362f6a37cf903631494e8784471931"
}
],
"tasks": {
"SAD": {
"task_trait": "REGION_SCORER",
"task_type": "SAD",
"message_type": "REGION_SCORER_RESULT",
"analysis": {
"region": [
{
"start_t": 1.06,
"end_t": 2.65,
"class_id": "speech",
"score": 0.0
},
{
"start_t": 3.19,
"end_t": 4.18,
"class_id": "speech",
"score": 0.0
},
{
"start_t": 4.84,
"end_t": 10.54,
"class_id": "speech",
"score": 0.0
},
{
"start_t": 10.99,
"end_t": 16.63,
"class_id": "speech",
"score": 0.0
},
{
"start_t": 16.91,
"end_t": 18.18,
"class_id": "speech",
"score": 0.0
},
{
"start_t": 18.25,
"end_t": 19.66,
"class_id": "speech",
"score": 0.0
},
{
"start_t": 21.11,
"end_t": 24.26,
"class_id": "speech",
"score": 0.0
}
]
},
"plugin": "sad-dnn-v7.0.1",
"domain": "multi-v1"
},
"LID": {
"task_trait": "GLOBAL_SCORER",
"task_type": "LID",
"message_type": "GLOBAL_SCORER_RESULT",
"analysis": {
"score": [
{
"class_id": "eng",
"score": 1.3094566
},
{
"class_id": "tgl",
"score": -2.0286703
},
{
"class_id": "apc",
"score": -2.3600318
},
{
"class_id": "pus",
"score": -2.6724625
},
{
"class_id": "arb",
"score": -2.8804097
},
{
"class_id": "arz",
"score": -3.0850184
},
{
"class_id": "fas",
"score": -3.1287756
},
{
"class_id": "tur",
"score": -3.1409845
},
{
"class_id": "spa",
"score": -4.291254
},
{
"class_id": "yue",
"score": -4.695897
},
{
"class_id": "urd",
"score": -5.4247284
},
{
"class_id": "fre",
"score": -6.19234
},
{
"class_id": "tha",
"score": -7.447339
},
{
"class_id": "vie",
"score": -7.9231014
},
{
"class_id": "kor",
"score": -8.1033945
},
{
"class_id": "jpn",
"score": -9.810704
},
{
"class_id": "cmn",
"score": -10.923913
},
{
"class_id": "rus",
"score": -11.114039
},
{
"class_id": "amh",
"score": -19.474201
}
]
},
"plugin": "lid-embedplda-v2.0.1",
"domain": "multi-v1"
},
"SID": {
"task_trait": "GLOBAL_SCORER",
"task_type": "SID",
"message_type": "GLOBAL_SCORER_RESULT",
"analysis": {
"score": [
{
"class_id": "test_speaker",
"score": -3.035223
}
]
},
"plugin": "sid-dplda-v2.0.1",
"domain": "multi-v1"
}
}
}
]
In the above example, results for SAD, LID, and SID analysis are output.
Enrollment Request
Some workflows support enrollment for one or more jobs. To list the jobs that support enrollment in a workflow, use the OliveWorkflow get_enrollment_job_names method:
>>> import olivepy.api.olive_async_client as oc, os
>>> import olivepy.api.workflow as ow
>>> from olivepy.messaging.msgutil import InputTransferType
>>> client = oc.AsyncOliveClient("example client")
>>> client.connect()
>>> owd = ow.OliveWorkflowDefinition("~/olive/sad-lid-sid_enroll-lid-sid_example.workflow")
>>> workflow = owd.create_workflow(client)
>>> workflow.get_analysis_tasks()
['SAD', 'LID', 'SID']
>>> print("Enrollment Jobs: {}".format(workflow.get_enrollment_job_names()))
Enrollment jobs '['SID Enrollment', 'LID Enrollment']'
Shown above, a workflow that supports SAD, LID, and SID analysis, while also supporting SID and/or LID enrollment. To enroll a speaker (generically a class id) via this workflow, use the OliveWorkflow's enroll method:
...
>>> buffer = workflow.package_audio('~/olive/English.wav', InputTransferType.SERIALIZED, label=os.path.basename('English.wav'))
>>> response = workflow.enroll([buffer], 'example speaker', ['SID Enrollment'])
>>> print(response.to_json(indent=1))
Which prints:
[
{
"job_name": "SID Enrollment",
"data": [
{
"data_id": "English.wav",
"msg_type": "PREPROCESSED_AUDIO_RESULT",
"mode": "MONO",
"merged": false,
"sample_rate": 8000,
"duration_seconds": 5.0,
"number_channels": 1,
"label": "English.wav",
"id": "32b34b7a675e47c0a4eb7a6a6ff8cc5d470beafda6cf6e53c5a12b4f711ea37a"
}
],
"tasks": {
"SID Enrollment": {
"task_trait": "CLASS_MODIFIER",
"task_type": "SID",
"message_type": "CLASS_MODIFICATION_RESULT",
"analysis": {
"addition_result": [
{
"successful": true,
"label": "English.wav"
}
]
},
"plugin": "sid-dplda-v2.0.1",
"domain": "multi-v1",
"class_id": "example speaker"
}
}
}
]
NOTE: since there was only one enrollment job, the enrollment request could have been made without specifying the job name (as shown below). Not specifying the job name will result in enrolling for all jobs, so it is a best practice to explicitly request the enrollment job.
...
response = workflow.enroll([buffer], 'example speaker')
...
To confirm the new class/speaker name was added:
>>> class_status_response = workflow.get_analysis_class_ids()
>>> print("Analysis Class Info: {}".format(class_status_response.to_json(indent=1)))
Analysis Class Info: {
"job_class": [
{
"job_name": "SAD, LID, SID analysis with LID and/or SID enrollment",
"task": [
{
"task_name": "SAD",
"class_id": [
"speech"
]
},
{
"task_name": "LID",
"class_id": [
"amh",
"apc",
"arb",
"arz",
"cmn",
"eng",
"fas",
"fre",
"jpn",
"kor",
"pus",
"rus",
"spa",
"tgl",
"tha",
"tur",
"urd",
"vie",
"yue"
]
},
{
"task_name": "SID",
"class_id": [
"test_speaker",
"example speaker"
]
}
]
}
]
}
Workflow job that support enrollment, often support un-enrollment. Use the get_unenrollment_job_names() message to list jobs that support unenrollment:
>>> print("Unenrollment jobs: {}".format(workflow.get_unenrollment_job_names()))
Unenrollment jobs: ['SID Unenrollment', 'LID Unenrollment']
>>> response = workflow.unenroll('example speaker', ['SID Unenrollment'])
>>> print("Workflow unenrollment: {}".format(response.to_json(indent=1)))
Workflow unenrollment: [
{
"job_name": "SID Unenrollment",
"data": [],
"tasks": {
"SID Unenroll": {
"task_trait": "CLASS_MODIFIER",
"task_type": "SID",
"message_type": "CLASS_MODIFICATION_RESULT",
"analysis": {},
"plugin": "sid-dplda-v2.0.1",
"domain": "multi-v1",
"class_id": "example speaker"
}
}
}
]
Running workflow.get_analysis_class_ids() again would show that 'example speaker' was removed.
Other Enrollment Options
Enrollment can also be done via the Python CLI tool, olivepyenroll:
olivepyenroll -p sid-embed-v6.0.1 --domain multicond-v1 -e Test_Speaker -w test.wav
Or incorporate the code from OliveClient (or AsyncOliveClient if client your client needs non-blocking calls):
>>> import olivepy.api.oliveclient as oc
client = oc.OliveClient('test client')
client.enroll('sid-embed-v6.0.1', 'multicond-v1', 'Test_Speaker', '/olive/data/test.wav')
Advanced Workflow Features
Audio Submission Options
Audio can be submitted as a path name or as a buffer. If submitted as a path name, then the path must be accessible by the OLIVE server. If submitting audio as a buffer then that buffer can contain either:
- A 'serialized' file, where the file contents are read into a buffer.
- PCM-16 encoded samples. If the client has decoded a audio source, then those samples can be submitted directly in the audio buffer.
The audio pathname or buffer is wrapped in a WorkflowDataRequest object before submitting to OLIVE.
As of OLIVE 5.3, a serialized video file (that contains audio) can also be submitted as a serialized buffer or pathname for audio processing.
Sending a local file as a serialized buffer:
...
# Submit the serialized audio file into a buffer for submission to OLIVE
>>> audio_filename = "~/audio/test_audio.wav"
# OliveWorkflow provides a helper method to serialize a file:
# Wrap the serialized audio buffer in a WorkflowDataRequest:
>>> olive_data = workflow.package_audio(audio_filename, InputTransferType.SERIALIZED, label=os.path.basename(audio_filename))
Or to send the path to a local file (assuming the server and client are running on the same host or have access to a shared file system):
...
# Submit the path of the audio file:
>>> audio_filename = "~/audio/test_audio.wav"
>>> olive_data = workflow.package_audio(audio_filename, mode=msgutil.InputTransferType.PATH)
Once the data has been wrapped in a WorkflowDataRequest it can be submitted for analysis or enrollment. An example of the AUDIO_DECODED transfer is not provided since, decoded audio requires a 3rd party package to decode audio input.
Audio Annotations
The audio submitted for analysis (or enrollment) can be annotated with start/end regions when packaging audio using the OliveWorkflow.package_audio() method. For example, here is how to specify two regions within a file:
...
>>> filename = '/home/olive/test.wav'
# Provide annotations for two regions: 0.3 to 1.7 seconds, and 2.4 to 3.3 seconds in filename:
>>> regions = [(0.3, 1.7), (2.4, 3.3)]
>>> audio = workflow.package_audio(filename, InputTransferType.AUDIO_SERIALIZED, annotations=regions)
...
Binary Data
New since OLIVE 5.3 is the ability to send audio or other data types such as Video or Images in a more generic container, BinaryMedia, which can contain audio, video, or image data (either as a serialzied file buffer or as filepath, decoded data is NOT supported with this message type). Replace calls to OliveWorkflow.package_audio() with OliveWorkflow.package_binary() to use this new data container.
Handling A Workflow Analysis Response (Python)
A successful Workflow analysis produces a response that includes information about the audio analyzed and the results of one or more tasks. The Workflow API includes the method, workflow.get_analysis_tasks(), to help clients identify and prepare for the types of tasks a Workflow will produce. The method, get_analysis_tasks(), returns the names of the tasks supported by this workflow.
For example:
>>> print("Analysis Tasks: {}".format(workflow.get_analysis_tasks()))
Analysis Tasks: ['SAD', 'LID']
For detailed information about the tasks():
>>> workflow_def_json = owd.to_json(indent=1)
# Pretty print the workflow definition:
>>> print(workflow_def_json)
{
"order": [
{
"workflow_type": "WORKFLOW_ANALYSIS_TYPE",
"job_definition": [
{
"job_name": "SAD, LID, SID analysis with LID and/or SID enrollment",
"tasks": [
{
"message_type": "REGION_SCORER_REQUEST",
"message_data": {
"plugin": "sad-dnn-v7.0.1",
"domain": "multi-v1"
},
"trait_output": "REGION_SCORER",
"task": "SAD",
"consumer_data_label": "audio",
"consumer_result_label": "SAD",
"return_result": true
},
{
"message_type": "GLOBAL_SCORER_REQUEST",
"message_data": {
"plugin": "lid-embedplda-v2.0.1",
"domain": "multi-v1"
},
"trait_output": "GLOBAL_SCORER",
"task": "LID",
"consumer_data_label": "audio",
"consumer_result_label": "LID",
"return_result": true
},
{
"message_type": "GLOBAL_SCORER_REQUEST",
"message_data": {
"plugin": "sid-dplda-v2.0.1",
"domain": "multi-v1"
},
"trait_output": "GLOBAL_SCORER",
"task": "SID",
"consumer_data_label": "audio",
"consumer_result_label": "SID",
"return_result": true
}
],
"data_properties": {
"min_number_inputs": 1,
"max_number_inputs": 1,
"type": "AUDIO",
"preprocessing_required": true,
"resample_rate": 8000,
"mode": "MONO"
}
}
],
"order_name": "Analysis Order"
},
{
"workflow_type": "WORKFLOW_ENROLLMENT_TYPE",
"job_definition": [
{
"job_name": "SID Enrollment",
"tasks": [
{
"message_type": "CLASS_MODIFICATION_REQUEST",
"message_data": {
"plugin": "sid-dplda-v2.0.1",
"domain": "multi-v1",
"class_id": "none"
},
"trait_output": "CLASS_MODIFIER",
"task": "SID",
"consumer_data_label": "audio",
"consumer_result_label": "SID Enrollment",
"return_result": true,
"allow_failure": false
}
],
"data_properties": {
"min_number_inputs": 1,
"max_number_inputs": 1,
"type": "AUDIO",
"preprocessing_required": true,
"resample_rate": 8000,
"mode": "MONO"
},
"description": "SID Enrollment"
},
{
"job_name": "LID Enrollment",
"tasks": [
{
"message_type": "CLASS_MODIFICATION_REQUEST",
"message_data": {
"plugin": "lid-embedplda-v2.0.1",
"domain": "multi-v1",
"class_id": "none"
},
"trait_output": "CLASS_MODIFIER",
"task": "LID",
"consumer_data_label": "audio",
"consumer_result_label": "LID Enrollment",
"return_result": true,
"allow_failure": false
}
],
"data_properties": {
"min_number_inputs": 1,
"max_number_inputs": 1,
"type": "AUDIO",
"preprocessing_required": true,
"resample_rate": 8000,
"mode": "MONO"
},
"description": "LID Enrollment"
}
],
"order_name": "Enrollment Order"
},
{
"workflow_type": "WORKFLOW_UNENROLLMENT_TYPE",
"job_definition": [
{
"job_name": "SID Unenrollment",
"tasks": [
{
"message_type": "CLASS_REMOVAL_REQUEST",
"message_data": {
"plugin": "sid-dplda-v2.0.1",
"domain": "multi-v1",
"class_id": "none"
},
"trait_output": "CLASS_MODIFIER",
"task": "SID",
"consumer_data_label": "",
"consumer_result_label": "SID Unenroll",
"return_result": true,
"allow_failure": false
}
],
"data_properties": {
"min_number_inputs": 1,
"max_number_inputs": 1,
"type": "AUDIO",
"preprocessing_required": true,
"resample_rate": 8000,
"mode": "MONO"
},
"description": "SID UNenrollment job "
},
{
"job_name": "LID Unenrollment",
"tasks": [
{
"message_type": "CLASS_REMOVAL_REQUEST",
"message_data": {
"plugin": "lid-embedplda-v2.0.1",
"domain": "multi-v1",
"class_id": "none"
},
"trait_output": "CLASS_MODIFIER",
"task": "LID",
"consumer_data_label": "",
"consumer_result_label": "LID Unenroll",
"return_result": true,
"allow_failure": false
}
],
"data_properties": {
"min_number_inputs": 1,
"max_number_inputs": 1,
"type": "AUDIO",
"preprocessing_required": true,
"resample_rate": 8000,
"mode": "MONO"
},
"description": "LID UNenrollment job "
}
],
"order_name": "Unenrollment Order"
}
],
"actualized": false,
"created": {
"year": 2021,
"month": 6,
"day": 29,
"hour": 8,
"min": 0,
"sec": 0
}
}
In the above example, the 'trait_output' attribute, identifies the type of score out produced by the task. This attribute lets clients know the type of score produced by this task. Currently, Workflow tasks return one of these three score (analysis) types:
- FRAME_SCORER - these tasks create a set of scores for each frame in the submitted audio. Typically frame scoring is returned by SAD plugins to provide a set of frame scores for 'speech'. For users of the Enterprise API, this the output from a FrameScorerResult message.
- GLOBAL_SCORER - these tasks create a single set of scores (one per class) for an entire audio. In the Enterprise API this maps to a GlobalScorerResult message.
- REGION_SCORER - these tasks create a set of scores for regions in the audio submission. In the Enterprise API this maps to a RegionScorerResult message
Parsing Analysis Output
Analysis output is grouped into one or more 'jobs', where a job is the audio info plus the analysis task result(s). In the example above, a single audio file was serialized, then submitted to OLIVE for analysis by SAD and LID tasks. This resulted in an OLIVE response containing the SAD and LID task results, plus information about the audio used for analysis. Since only one file was submitted for analysis, only one 'job' was returned. Had two audio files been submitted, then OLIVE would have created two job results - one for each file submitted.
Each job will have a data element that describes properties of the audio used for analysis and one or more 'task' elements that contain the analysis results which are either frame scores, global scores, or region scores.
Frame Scorer Task Output
Tasks that return frame scores, are based on the Enterprise API FrameScoreResult message:
// The results from a FrameScorerRequest
message FrameScorerResult {
repeated FrameScores result = 1; // List of frame scores by class_id
}
// The basic unit of a frame score, returned in a FrameScorerRequest
message FrameScores {
required string class_id = 1; // The class id to which the frame scores pertain
required int32 frame_rate = 2; // The number of frames per second
required double frame_offset = 3; // The offset to the center of the frame 'window'
repeated double score = 4 [packed=true]; // The frame-level scores for the class_id
}
The JSON output for frame score results has the form:
result[ {classId:str, frameRate:int, frameOffset:double, score:[double]} ]
Here is an example of SAD output as frame scores:
"tasks": {
...
"SAD": {
"task_trait": "FRAME_SCORER",
"task_type": "SAD",
"message_type": "FRAME_SCORER_RESULT",
"analysis": {
"result": [
{
"class_id": "speech",
"frame_rate": 100,
"frame_offset": 0.0,
"score": [
-1.65412407898345,
-1.65412407898345,
-1.6976179167708825,
-1.7201831820448585,
-1.7218198748053783,
-1.7285406659981328,
-1.7403455556231222,
-1.7572345436803467,
-1.779207630169806,
-1.8052880586341415,
...
]
}
]
},
"plugin": "sad-dnn",
"domain": "multi-v1"
},
Global Scorer Tasks
Tasks that return global scores, are based on the Enterprise API's GlobalScorerResult message:
message GlobalScorerResult {
repeated GlobalScore score = 1; // The class scores
}
// The global score for a class
message GlobalScore {
required string class_id = 1; // The class
required float score = 2; // The score associated with the class
optional float confidence = 3; // An optional confidence value when part of a calibration report
optional string comment = 4; // An optional suggested action when part of a calibration report
}
The JSON output for global score results has the form:
score[ {classId:str, score:[float]} ]
Here is an example of LID output as global scores:
"tasks": {
...
"LID": {
"task_trait": "GLOBAL_SCORER",
"task_type": "LID",
"message_type": "GLOBAL_SCORER_RESULT",
"analysis": {
"score": [
{
"class_id": "eng",
"score": 2.5195693969726562
},
{
"class_id": "apc",
"score": -3.509812355041504
},
{
"class_id": "tgl",
"score": -3.566483974456787
},
{
"class_id": "arb",
"score": -3.994529962539673
},
{
"class_id": "fre",
"score": -21.55596160888672
}
]
},
"plugin": "lid-embedplda",
"domain": "multi-v1"
}
Region Scorer Tasks
Tasks that return region scores, are based on the Enterprise API's RegionScorerResult message:
// The region score result
message RegionScorerResult {
repeated RegionScore region = 1; // The scored regions
}
// The basic unit a region score. There may be multiple RegionScore values in a RegionScorerResult
message RegionScore {
required float start_t = 1; // Begin-time of the region (in seconds)
required float end_t = 2; // End-time of t he region (in seconds)
required string class_id = 3; // Class ID associated with region
optional float score = 4; // Optional score associated with the class_id label
}
The JSON output for region score results has the form:
score[ {
startT:float,
endT:float,
classId:str,
score:float
} ]
Here is an example of SAD output as region score:
"tasks": {
"SAD": {
"task_trait": "REGION_SCORER",
"task_type": "SAD",
"message_type": "REGION_SCORER_RESULT",
"analysis": {
"region": [
{
"start_t": 3.3399999141693115,
"end_t": 10.5,
"class_id": "speech",
"score": 0.0
}
]
},
"plugin": "sad-dnn",
"domain": "vtd-v1"
},
Enrolled Classes
To list the current classes (such as speakers for a SID task, or languages for LID) in an analysis workflow, use the OliveWorkflow get_analysis_class_ids method:
>>> import olivepy.api.olive_async_client as oc
>>> import olivepy.api.workflow as ow
>>> client = oc.AsyncOliveClient("example client")
>>> client.connect()
>>> owd = ow.OliveWorkflowDefinition("~/olive/sad_lid_sid.workflow")
>>> workflow = owd.create_workflow(client)
>>> class_status_response = workflow.get_analysis_class_ids()
>>> print("Task Class IDs: {}".format(class_status_response.to_json(indent=1)))
Enrollment Class IDs:
[
{
"job_name": "SAD LID, SID",
"tasks": {
"SAD": {
"class_id": [
"speech"
]
},
"LID": {
"class_id": [
"amh",
"apc",
"arb",
"arz",
"cmn",
"eng",
"fas",
"fre",
"jpn",
"kor",
"pus",
"rus",
"spa",
"tgl",
"tha",
"tur",
"urd",
"vie",
"yue"
]
},
"SID": {
"class_id": [
"test speaker"
]
}
}
}
]
Note that some tasks, such as SID, support enrollment, so the list of class IDs can can change over time as new enrollments are added.
Multi-channel Audio
The default workflow behavior is to merge multi-channel audio into a single channel, which is known as 'MONO' mode. To perform analysis on each channel instead of a merged channel, then the Workflow Definition must be authored with a data mode of 'SPLIT'. When using the split mode, each channel in a multi-channel audio input is "split" into a job.
Here is a typical workflow that merges any multi-channel audio into a single channel audio input:
>>> import olivepy.api.olive_async_client as oc
>>> import olivepy.api.workflow as ow
>>> client = oc.AsyncOliveClient("example client")
>>> client.connect()
>>> owd = ow.OliveWorkflowDefinition("~/olive/sad_lid_sid.workflow")
>>> workflow = owd.create_workflow(client)
>>> print(workflow.get_analysis_task_info())
[
{
"Data Input": {
"min_number_inputs": 1,
"max_number_inputs": 1,
"type": "AUDIO",
"preprocessing_required": true,
"resample_rate": 8000,
"mode": "MONO"
},
...
Here is a workflow that will split each channel in a multi-channel (stereo) audio input into separate jobs:
>>> import olivepy.api.olive_async_client as oc
>>> import olivepy.api.workflow as ow
>>> client = oc.AsyncOliveClient("example client")
>>> client.connect()
>>> owd = ow.OliveWorkflowDefinition("~/olive/stereo_sid_example.workflow")
>>> workflow = owd.create_workflow(client)
>>> print(workflow.get_analysis_task_info())
[
{
"Data Input": {
"min_number_inputs": 1,
"max_number_inputs": 1,
"type": "AUDIO",
"preprocessing_required": true,
"resample_rate": 8000,
"mode": "SPLIT"
},
The above Workflow Definition when applied to stereo file will produce a set of SID scores for each channel.
Adaption Using a Workflow
Not yet implemented via a Workflow. The adaption process is complicated, time-consuming, and plugin/domain specific. Until Adaptation via a workflow is implemented, please use the SRI provided Python client (olivepylearn) or Java client (OliveLearn) to perform adaptation.
To adapt using the olivepylearn utility:
olivepylearn --plugin sad-dnn --domain multi-v1 -a TEST_NEW_DOMAIN -i /olive/sadRegression/lists/adapt_s.lst
Where that adapt_s.lst looks like this:
/olive/sadRegression/audio/adapt/20131209T225239UTC_10777_A.wav S 20.469 21.719
/olive/sadRegression/audio/adapt/20131209T225239UTC_10777_A.wav NS 10.8000 10.8229
/olive//sadRegression/audio/adapt/20131209T234551UTC_10782_A.wav S 72.898 73.748
/olive//sadRegression/audio/adapt/20131209T234551UTC_10782_A.wav NS 42.754 43.010
/olive//sadRegression/audio/adapt/20131210T184243UTC_10791_A.wav S 79.437 80.427
/olive//sadRegression/audio/adapt/20131210T184243UTC_10791_A.wav NS 61.459 62.003
/olive//sadRegression/audio/adapt/20131212T030311UTC_10817_A.wav S 11.0438 111.638
/olive//sadRegression/audio/adapt/20131212T030311UTC_10817_A.wav NS 69.058 73.090
/olive//sadRegression/audio/adapt/20131212T052052UTC_10823_A.wav S 112.936 113.656
/olive//sadRegression/audio/adapt/20131212T052052UTC_10823_A.wav NS 83.046 83.114
/olive//sadRegression/audio/adapt/20131212T064501UTC_10831_A.wav S 16.940 20.050
/olive//sadRegression/audio/adapt/20131212T064501UTC_10831_A.wav NS 59.794 59.858
/olive//sadRegression/audio/adapt/20131212T084501UTC_10856_A.wav S 87.280 88.651
/olive//sadRegression/audio/adapt/20131212T084501UTC_10856_A.wav NS 82.229 82.461
/olive//sadRegression/audio/adapt/20131212T101501UTC_10870_A.wav S 111.346 111.936
/olive//sadRegression/audio/adapt/20131212T101501UTC_10870_A.wav NS 83.736 84.446
/olive//sadRegression/audio/adapt/20131212T104501UTC_10876_A.wav S 77.291 78.421
/olive//sadRegression/audio/adapt/20131212T104501UTC_10876_A.wav NS 0 4.951
/olive//sadRegression/audio/adapt/20131212T111501UTC_10878_A.wav S 30.349 32.429
/olive//sadRegression/audio/adapt/20131212T111501UTC_10878_A.wav NS 100.299 101.647
/olive//sadRegression/audio/adapt/20131212T114501UTC_10880_A.wav S 46.527 49.147
/olive//sadRegression/audio/adapt/20131212T114501UTC_10880_A.wav NS 44.747 46.148
/olive//sadRegression/audio/adapt/20131212T134501UTC_10884_A.wav S 24.551 25.471
/olive//sadRegression/audio/adapt/20131212T134501UTC_10884_A.wav NS 52.033 52.211
/olive//sadRegression/audio/adapt/20131212T141502UTC_10887_A.wav S 88.358 93.418
/olive//sadRegression/audio/adapt/20131212T141502UTC_10887_A.wav NS 46.564 46.788
/olive//sadRegression/audio/adapt/20131212T151501UTC_10895_A.wav S 10.507 11.077
/olive//sadRegression/audio/adapt/20131212T151501UTC_10895_A.wav NS 41.099 41.227
/olive//sadRegression/audio/adapt/20131212T154502UTC_10906_A.wav S 61.072 63.002
/olive//sadRegression/audio/adapt/20131212T154502UTC_10906_A.wav NS 19.108 19.460
/olive//sadRegression/audio/adapt/20131213T023248UTC_10910_A.wav S 97.182 97.789
/olive//sadRegression/audio/adapt/20131213T023248UTC_10910_A.wav NS 71.711 71.732
/olive//sadRegression/audio/adapt/20131213T041143UTC_10913_A.wav S 114.312 117.115
/olive//sadRegression/audio/adapt/20131213T041143UTC_10913_A.wav NS 31.065 31.154
/olive//sadRegression/audio/adapt/20131213T044200UTC_10917_A.wav S 90.346 91.608
/olive//sadRegression/audio/adapt/20131213T044200UTC_10917_A.wav NS 50.028 51.377
/olive//sadRegression/audio/adapt/20131213T050721UTC_10921_A.wav S 75.986 76.596
/olive//sadRegression/audio/adapt/20131213T050721UTC_10921_A.wav NS 12.485 12.709
/olive//sadRegression/audio/adapt/20131213T071501UTC_11020_A.wav S 72.719 73.046
/olive//sadRegression/audio/adapt/20131213T071501UTC_11020_A.wav NS 51.923 53.379
/olive//sadRegression/audio/adapt/20131213T104502UTC_18520_A.wav NS 11.1192 112.761
/olive//sadRegression/audio/adapt/20131213T121501UTC_18530_A.wav NS 81.277 82.766
/olive//sadRegression/audio/adapt/20131213T124501UTC_18533_A.wav NS 83.702 84.501
/olive//sadRegression/audio/adapt/20131213T134502UTC_18567_A.wav NS 69.379 72.258
/olive//sadRegression/audio/adapt/20131217T015001UTC_18707_A.wav NS 5.099 10.507
You may also incorporate the adapt code from olivepy.oliveclient directly into your client:
# Setup processing variables (get this config or via command line options
plugin = "sad-dnn"
domain = "multi-v1"
new_domain_name = "python_adapted_multi-v2"
# Build the list of files plus the regions in the those files to adapt by parsing the input file:
file_annotations = self.parse_annotation_file("lists/adapt.lst")
return self.adapt_supervised_old(plugin, domain, file_annotations, new_domain_name)
Python Workflow Example
As previously mentioned, SRI distributes Workflow Definitions as files, which are preconfigured to perform tasks such as SAD, LID, SID, etc. The example below uses a Workflow Definition file with the SRI implemented Python Workflow API to make a SAD and LID request via a Workflow Definition file:
import os, json, sys
import olivepy.api.olive_async_client as oc
import olivepy.api.workflow as ow
import olivepy.messaging.msgutil as msgutil
from olivepy.messaging.msgutil import InputTransferType
# Create a connection to a local OLIVE server
client = oc.AsyncOliveClient("test olive client", 'localhost')
client.connect()
# Example workflow definition file:
workflow_filename = "~/olive/sad_lid_example.workflow"
workflow_def = ow.OliveWorkflowDefinition(workflow_filename)
# Submit the workflow definition to the client for actualization (instantiation or sometimes called activation):
workflow = workflow_def.create_workflow(client)
# Prepare a audio file to submit (as a serialzied file)
audio_filename = "~/olive/sad_smoke.wav"
buffers = []
# read in the file as raw bytes so a buffer can be sent to the server as a buffer:
data_wrapper = workflow.package_audio(audio_filename, InputTransferType.SERIALIZED, label=audio_filename)
buffers.append(data_wrapper)
# OR - if the server and client share a filesystem, uncomment the following to send the path to the audio file instead of a buffer:
# data_wrapper = workflow.package_audio(audio_filename, mode=msgutil.InputTransferType.PATH)
# Submit the workflow to OLIVE for analysis:
response = workflow.analyze(buffers)
# response will contain an error message if the workflow failed, or results for each task:
print("Workflow results:")
print("{}".format(response.to_json(1)))
# Be sure to close the connection to the server when done
client.disconnect()
For the above code, one would see JSON formatted output like this (of course your output will vary by the audio submitted for analysis):
Workflow results:
[
{
"job_name": "Basic SAD and LID workflow",
"data": [
{
"data_id": "~/olive/sad_smoke.wav",
"msg_type": "PREPROCESSED_AUDIO_RESULT",
"mode": "MONO",
"merged": false,
"sample_rate": 8000,
"duration_seconds": 27.9325,
"number_channels": 1,
"label": "~/olive/sad_smoke.wav",
"id": "ebc1dfa7502841216526768a3f94b095b9362f6a37cf903631494e8784471931"
}
],
"tasks": {
"Speech Regions": {
"task_trait": "REGION_SCORER",
"task_type": "SAD",
"message_type": "REGION_SCORER_RESULT",
"analysis": {
"region": [
{
"start_t": 1.06,
"end_t": 2.65,
"class_id": "speech",
"score": 0.0
},
{
"start_t": 3.19,
"end_t": 4.18,
"class_id": "speech",
"score": 0.0
},
{
"start_t": 4.84,
"end_t": 10.54,
"class_id": "speech",
"score": 0.0
},
{
"start_t": 10.99,
"end_t": 16.63,
"class_id": "speech",
"score": 0.0
},
{
"start_t": 16.91,
"end_t": 18.18,
"class_id": "speech",
"score": 0.0
},
{
"start_t": 18.25,
"end_t": 19.66,
"class_id": "speech",
"score": 0.0
},
{
"start_t": 21.11,
"end_t": 24.26,
"class_id": "speech",
"score": 0.0
}
]
},
"plugin": "sad-dnn",
"domain": "multi-v1"
},
"LID": {
"task_trait": "GLOBAL_SCORER",
"task_type": "LID",
"message_type": "GLOBAL_SCORER_RESULT",
"analysis": {
"score": [
{
"class_id": "eng",
"score": 1.3094566
},
{
"class_id": "tgl",
"score": -2.0286703
},
{
"class_id": "apc",
"score": -2.3600318
},
{
"class_id": "pus",
"score": -2.6724625
},
{
"class_id": "arb",
"score": -2.8804097
},
{
"class_id": "arz",
"score": -3.0850184
},
{
"class_id": "fas",
"score": -3.1287756
},
{
"class_id": "tur",
"score": -3.1409845
},
{
"class_id": "spa",
"score": -4.291254
},
{
"class_id": "yue",
"score": -4.695897
},
{
"class_id": "urd",
"score": -5.4247284
},
{
"class_id": "fre",
"score": -6.19234
},
{
"class_id": "tha",
"score": -7.447339
},
{
"class_id": "vie",
"score": -7.9231014
},
{
"class_id": "kor",
"score": -8.1033945
},
{
"class_id": "jpn",
"score": -9.810704
},
{
"class_id": "cmn",
"score": -10.923913
},
{
"class_id": "rus",
"score": -11.114039
},
{
"class_id": "amh",
"score": -19.474201
}
]
},
"plugin": "lid-embedplda-v2.0.1",
"domain": "multi-v1"
}
}
}
]
Creating a Workflow Definition
Internally, the OLIVE design uses a simple kitchen metaphor, which is expressed in the elements that compose an OLIVE workflow. If one thinks of OLIVE as a kitchen, orders are submitted to OLIVE, which are then extracted into jobs that are cooked/executed (as tasks). In this analogy, when authoring OLIVE workflows you are authoring both a menu and a recipe. Clients use the Workflow to request an order (analysis, enrollment, unenrollment), while the Workflow also includes the recipe to cook/execute those orders.
The "job" portion of a Workflow is used to build a simple directed acyclic graph (DAG) within OLIVE. This DAG, which OLIVE refers to as a "Job Graph", allows data to be shared by multiple tasks, while also allowing connections between these tasks. When connected, the outputs of upstream tasks (tasks that have been executed) and provided to downstream tasks (tasks that have not yet been executed). For example the output of a SAD task can be supplied to one or more downstream tasks such as LID or SID, so those tasks do not have to internally run SAD.
To enable this complexity, the workflow recipe defines a set of elements/objects:
- WorkflowDefinition - The outer container for all orders and their jobs (Job Graphs)
- WorkflowOrderDefinition - Used to group jobs into processing pipelines for analysis, enrollment, or unenrollment activities
- JobDefinition - Defines the set of tasks that are executed in a DAG and how task output is shared/returned. To simplify authoring, tasks in a job are executed sequentially.
- WorkflowTask - The task that is executed, which is usually implemented by a plugin
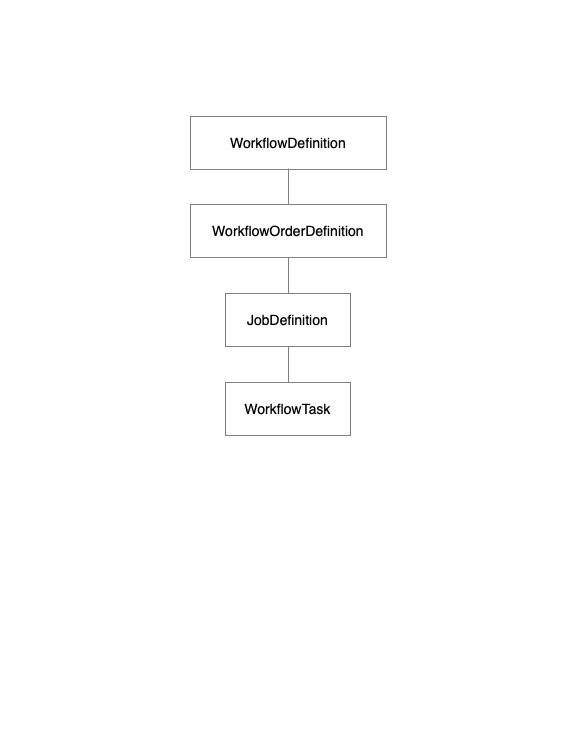
A quick note on the structure of elements: The WorkflowDefinition, WorkflowOrderDefinition, JobDefinition, and WorkflowTask are all based on a Protobuf message of the same name in the Enterprise API. Should you have questions about these elements it maybe be helpful to refer to these protobuf messages; however, the relationship between these messages/elements is not clear when looking at the Enterprise API messages, so the tables below include a "cardinality" column to make it clearer about the relationship between these elements.
WorkflowDefinition
At the top-level, the Workflow Definition element includes these required and optional fields:
| Attribute | Type | Cardinality | Description |
|---|---|---|---|
| order | WorkflowOrderDefinition | 1 to 3 | See WorkflowOrderDefinition below. There must be one or more of these elements |
| actualized | boolean | 1 | Always set to 'false' when creating a new Workflow. This is an internal field set by the OLIVE server when actualized |
| version | string | 0 or 1 | An optional user defined version number for this workflow |
| description | string | 0 or 1 | An optional description of this workflow |
| created | DateTime | 0 or 1 | An optional date this workflow was created |
| updated | DateTime | 0 or 1 | An optional date this workflow was updated |
An example Workflow Definition element (the WorkflowOrderDefinition element(s) within order defined later to avoid confusion )
{
"order": [],
"actualized": false,
"version": "1.0",
"description": "Example of a Workflow Definition Object",
"created": {
"year": 2021,
"month": 6,
"day": 29,
"hour": 8,
"min": 0,
"sec": 0
}
}
WorkflowOrderDefinition
Within a WorkflowDefinition element there can be 1 to 3 WorkflowOrderDefinition elements defined (one for analysis, one for enrollment, and one for unenrollment). The WorkflowOrderDefinition includes these required and optional fields:
| Attribute | Type | Cardinality | Description |
|---|---|---|---|
| workflow_type | WorkflowType | 1 | One of: 'WORKFLOW_ANALYSIS_TYPE', 'WORKFLOW_ENROLLMENT_TYPE', or 'WORKFLOW_UNENROLLMENT_TYPE' |
| job_definition | JobDefinition | 1 or more | See JobDefinition element below. An order must have at least one job |
| order_name | JobDefinition | 1 or more | See JobDefinition element below. An order must have at least one job |
Below is an example of a WorkflowOrderDefinition (JobDefinition element(s) defined later). 1 to 3 of these elements can be added to a WorkflowDefintion:
{
"workflow_type": "WORKFLOW_ANALYSIS_TYPE",
"job_definition": [],
"order_name": "Analysis Order"
}
JobDefinition
One or more JobDefinition elements must be added to WorkflowOrderDefinition element (see above). This element includes these required and optional fields:
| Attribute | Type | Cardinality | Description |
|---|---|---|---|
| job_name | string | 1 | A unique name for this job |
| tasks | WorkflowTask | 1 or more | See the WorkflowTask below. There must be at least one task defined for a Job. Assume tasks are executed in the order they are defined in this list. |
| data_properties | DataHandlerProperty | 1 | See DataHandlerProperty below. This defines the data (normally audio) properties for all tasks in this job |
| description | string | 0 or 1 | An optional description |
| processing_type | WorkflowJobType | 1 | Optional, do not specify unless creating a conditional workflow. The default value is "MERGE", with allowable values: "MERGE", "PARALLEL", or "SEQUENTIAL". See section on conditional workflows |
| conditional_job_output | boolean | 0 or 1 | Optional, do not specify unless creating a conditional workflow. See section on conditional workflows |
| dynamic_job_name | string | 0 or 1 | Optional, do not specify unless creating a conditional workflow. See section on conditional workflows |
| resolved | bool | 0 or 1 | DO NOT SET. This value is assgiend by the server |
| transfer_result_labels | string | 1 | Optional, do not specify unless creating a conditional workflow. See section on conditional workflows |
Here is an example of JobDefinition element (the WorkflowTask and DataHandlerProperty elements are defined below). One or more of these elements must be added to a WorkflowOrderDefinition.
[
{
"job_name": "SAD, LID, SID analysis with LID and SID enrollment",
"tasks": [],
"data_properties": {}
}
]
WorkflowTask
One or more WorkflowTask elements must be defined for a JobDefinition element (see above). This element includes these required and optional fields:
| Attribute | Type | Cardinality | Description |
|---|---|---|---|
| message_type | MessageType | 1 | The type of the task. One of: "REGION_SCORER_REQUEST", "GLOBAL_SCORER_REQUEST", "FRAME_SCORER_REQUEST", "AUDIO_ALIGN_REQUEST", "CLASS_MODIFICATION_REQUEST", "CLASS_REMOVAL_REQUEST", or "PLUGIN_2_PLUGIN_REQUEST" |
| message_data | varies | 1 | This element contains values based on the message type. For non-enrollment requests this is a dictionary that contains the keys 'plugin', and 'domain' For enrollment tasks, the dictionary also includes "class id": "None" |
| trait_output | TraitType | 1 | Classifies the type of output produced by this task. Must be one of: "GLOBAL_SCORER", 'REGION_SCORER', 'FRAME_SCORER', "CLASS_MODIFIER", "PLUGIN_2_PLUGIN", "AUDIO_ALIGNMENT_SCORER" |
| task | string | 1 | A label used to define the task type. By convention of one: "SAD", "LID", "SID", "LDD", "SDD", "QBE", "ASR", etc; however, one can define your own type name. For example if you prefere "STT" to "ASR" |
| consumer_data_label | string | 1 | This task consumes data data input having this name, which is 'audio' for almost all tasks. If using a non 'audio' lable, then this value must match a 'consumer_data_label' used in the workflow's DataHandlerProperty. |
| consumer_result_label | string | 1 | The unique name assigned to this task. Each task in a job must specify a unique name, which is often the same as task. One can also consider this 'task_id' |
| return_result | bool | 0 or 1 | If true, then output produced by this task is returned to the client. |
| option_mappings | OptionMap | 0 or more | This is used to connect the outputs from one or more upstream tasks to this (plugin) task. If one or more values are defined in this mapping, then any upstream (completed) tasks that produced output (defined by the tasks 'consumer_result_label') matching the value of 'workflow_keyword_name' are added to the option dictionary as 'plugin_keyword_name'. |
| allow_failure | bool | zero or 1 | If true, then this task can fail without stopping the execution of workflow. If false then a failure of this task will prevent downstream tasks/jobs from being ran |
| supported_options | OptionDefinition | 0 or more | DO NOT SET. This is set by the server when the workflow is actualized, letting clients know the options supported by the plugin/task available on the server |
| class_id | string | 0 or 1 | NOT YET SUPPORTED - class IDs can be added to the message_data section (if supported by the message type) |
| description | string | 0 or 1 | An optional description of this task |
Example of defining a SAD task:
{
"message_type": "REGION_SCORER_REQUEST",
"message_data": {
"plugin": "sad-dnn-v7.0.1",
"domain": "multi-v1"
},
"trait_output": "REGION_SCORER",
"task": "SAD",
"consumer_data_label": "audio",
"consumer_result_label": "SAD",
"return_result": true
}
Example of defining an enrollment task for a LID plugin (note the inclusion of class_id in the message_data element):
{
"message_type": "CLASS_MODIFICATION_REQUEST",
"message_data": {
"plugin": "lid-embedplda-v2.0.1",
"domain": "multi-v1",
"class_id": "none"
},
"trait_output": "CLASS_MODIFIER",
"task": "LID",
"consumer_data_label": "audio",
"consumer_result_label": "LID_Enroll",
"return_result": true,
"allow_failure": false
}
DataHandlerProperty
The JobDefinition element requires a DataHandlerProperty element that defines the type of data (currently only supporting 'audio') data handling properties used by tasks in the job. This element includes these required and optional fields:
| Attribute | Type | Cardinality | Description |
|---|---|---|---|
| min_number_inputs | int | 1 | The minimum number of data inputs required for a job. This value can be 0, but almost all tasks require 1 audio input. An audio comparison task is one of the few tasks that will require 2 inputs |
| max_number_inputs | int | 0 or 1 | Optional value, for furture use of batch processing of tasks that consume more than one input. This specifies the max number of data inputs consumed by task(s) in the job when doing batch processing, but is not currently used by any tasks |
| type | InputDataType | 1 | For now use "AUDIO", but can be one of "AUDIO", "VIDEO", "TEXT", or "IMAGE" |
| preprocessing_required | boolean | 1 | Set to 'true'. Not configurable at this time |
| resample_rate | int | 0 or 1 | Do not specify. Currently a value of 8000 is used |
| mode | MultiChannelMode | 0 or 1 | One of "MONO", "SPLIT", or "SELECTED". This determines how multi channel audio is handled in a workflow, with "MONO" being the default. In "MONO" mode, any multi channel data/audio is converted to mono when processed by task(s) in this job. For "SPLIT" each channel is handled by the task(s) in this job, so there is a set of results for each channel. For "SELECTED" a channel number must be provided when packaing the audio for the workflow and that channel is used for the job task(s) |
| consumer_data_label | string | 0 or 1 | Data supplied for Analysis, Enrollment, or Unenrollment is labeled by this name when passed to tasks within the job. Bu default use a value of 'audio' |
{
"data_properties": {
"min_number_inputs": 1,
"type": "AUDIO",
"preprocessing_required": true,
"mode": "MONO"
}
}
API Specification
Auto generated PyDoc
class olivepy.api.workflow.OliveWorkflowDefinition(filename)
Used to load a Workflow Definition from a file.
Parameters
- filename: the path/filename of a workflow definition file to load
get_json(indent=1)
Create a JSON structure of the Workflow
-
Returns
A JSON (dictionary) representation of the Workflow Definition
to_json(indent=None)
Generate the workflow as a JSON string
:indent: if a non-negative integer, then JSON array elements and object members will be pretty-printed with that indent level. An indent level of 0 will only insert newlines. None is the most compact representation. A negative value will return the JSON document
-
Returns
the Workflow Definition as as JSON string:
create_workflow(client)
Create a new, executable (actualized), Workflow, which can be used to make OLIVE analysis, enrollment, or adaptation requests
-
Parameters
client (
AsyncOliveClient) – an open client connection to an OLIVE server -
Returns
a new OliveWorkflow object, which has been actualized (activated) by the olive server
exception olivepy.api.workflow.WorkflowException()
This exception means that an error occurred handling a Workflow
class olivepy..workflow.OliveWorkflow(olive_async_client: olivepy.api.olive_async_client.AsyncOliveClient, actualized_workflow: olivepy.messaging.response.OliveWorkflowActualizedResponse)
An OliveWorkflow instance represents a Workflow Definition actualized by an OLIVE server. An OliveWorkflow instance is used to make analysis, or enrollment requests. An OliveWorkflow should be created using an OliveWorkflowDefinition's create_workflow() method. All calls to the server include an optional callback. When the callback is provided, the call does not block and the callback method is invoked when a response is received from the server. A callback method has 3 arguments: the original request, the response, and an error message if the request failed.
Parameters
filename: the name of the workflow definition file
Raises
WorkflowException – If the workflow was not actualized
get_analysis_job_names()
The names of analysis jobs in this workflow (usually only one analysis job)
Return type
`List`[`str`]
Returns
A list of analysis job names in this workflow
get_enrollment_job_names()
The names of enrollment jobs in this workflow. There should be one enrollment job for each analysis tasks that supports class enrollment
Return type
`List`[`str`]
Returns
A list of enrollment job names in this workflow
get_unenrollment_job_names()
The names of un-enrollment jobs in this workflow. There should be one un-enrollment job for each analysis task that supports class un-enrollment
-
Return type
List[str] -
Returns
A list of un-enrollment job names in this workflow
get_analysis_tasks(job_name=None)
Return a list of tasks supported by this workflow. These names are unique and can generally be assumed they are named after the task type (SAD, LID, SID, etc) they support but they could use alternate names if there are multiple tasks with the same task type in a workflow (for example a workflow could have a SAD task that does frame scoring and a SAD task that does regions scoring)
-
Parameters
job_name - (
Optional[str]) – filter the returned task names to those belonging to this job name. Optional since most workflows only support one analysis job. -
Return type
List[str]
Returns
A list of task names
get_enrollment_tasks(job_name=None, type=2)
Return a list of tasks that support enrollment in this workflow.
-
Parameters
job_name (
Optional[str]) – optionally the name of the enrollment job. Optional since most workflows only support one job -
Return type
List[str] -
Returns
a list of task names
get_unenrollment_tasks(job_name=None)
Return a list of tasks that support UNenrollment in this workflow.
-
Parameters
job_name (
Optional[str]) – optionally the name of the enrollment job. Optional since most workflows only support one job -
Return type
List[str] -
Returns
a list of task names
get_analysis_task_info()
A JSON like report of the tasks used for analysis from the actualized workflow. When possible, this report includes the plugins used in the workflow (although there can be cases when the final plugin/domain used is not known until runtime)
-
Return type
List[Dict[str,Dict]] -
Returns
JSON structured detailed information of analysis tasks used in this workflow
to_json(indent=None)
Generate the workflow as a JSON string
-
Parameters
indent: if a non-negative integer, then JSON array elements and object members will be pretty-printed with that indent level. An indent level of 0 will only insert newlines.
Noneis the most compact representation. A negative value will return the JSON document -
Returns
the Workflow Definition as as JSON string:
serialize_audio(filename)
Helper function used to read in an audio file and output a serialized buffer. Can be used with package_audio() when using the AUDIO_SERIALIZED mode and the audio input has not already been serialized
-
Parameters
filename (
str) – the local path to the file to serialize -
Return type
AnyStr -
Returns
the contents of the file as a byte buffer, otherwise an exception if the file can not be opened. This buffer contains the raw content of the file, it does NOT contain encoded samples
package_audio(audio_data, mode=, annotations=None, task_annotations=None, selected_channel=None, num_channels=None, sample_rate=None, num_samples=None, validate_local_path=True, label=None)
Creates an Audio object that can be submitted with a Workflow analysis, enrollment, or adapt request.
-
Parameters
-
audio_data (
AnyStr) – the input data is a string (file path) if mode is ‘AUDIO_PATH’, otherwise the input data is a binary buffer. Use serialize_audio() to serialize a file into a buffer, or pass in a list of PCM_16 encoded samples -
mode – specifies how the audio is sent to the server: either as (string) file path or as a binary buffer. NOTE: if sending a path, the path must be valid for the server.
-
annotations (
Optional[List[Tuple[float,float]]]) – optional regions (start/end regions in seconds) as a list of tuples (start_seconds, end_seconds) -
task_annotations (
Optional[Dict[str,Dict[str,List[Tuple[float,float]]]]]) – optional and more regions (start/end regions in seconds) targeted for a task and classifed by a lable (such as speech, non-speech, speaker). For example: {‘SHL’: {‘speaker’’:[(0.5, 4.5), (6.8, 9.2)]}, are annotations for the ‘SHL’ task, which are labeled as class ‘speaker’ having regions 0.5 to 4.5, and 6.8 to 9.2. Use get_analysis_tasks() to get the name of workflow tasks . -
selected_channel (
Optional[int]) – optional - the channel to process if using multi-channel audio -
num_channels (
Optional[int]) – The number of channels if audio input is a list of decoded (PCM-16) samples, if not using a buffer of PCM-16 samples this is value is ignored -
sample_rate (
Optional[int]) – The sample rate if audio input is a list of decoded (PCM-16) samples, if not using a buffer of PCM-16 samples this is value is ignored -
num_samples (
Optional[int]) – The number of samples if audio input is a list of decoded (PCM-16) samples, if not using a buffer of PCM-16 samples this is value is ignored -
validate_local_path (
bool) – If sending audio as as a string path name, then check that the path exists on the local filesystem. In some cases you may want to pass a path which is valid on the server but not this client so validation is not desired -
label – an optional name to use with the audio
-
-
Return type
WorkflowDataRequest -
Returns
A populated WorkflowDataRequest to use in a workflow activity
package_text(text_input)
Not yet supported
-
Parameters
text_input (
str) – a text input -
Return type
WorkflowDataRequest -
Returns
TBD
package_image(image_input)
Not yet supported
-
Parameters
image_input – An image input
-
Return type
WorkflowDataRequest -
Returns
TBD
package_video(video_input)
Not yet supported
-
Parameters
video_input – a video input
-
Return type
WorkflowDataRequest -
Returns
TBD
get_analysis_class_ids(callback=None)
Query OLIVE for the current class IDs (i.e. speaker names for SID, keywords for QbE, etc). For tasks that support enrollment, their class IDs can change over time.
-
Parameters
callback – an optional callback method that accepts a OliveClassStatusResponse object. Such as: my_callback(result : response.OliveClassStatusResponse)
-
Return type
OliveClassStatusResponse -
Returns
an OliveClassStatusResponse object if no callback specified, otherwise the callback receives the OliveClassStatusResponse object when a response is received from the OLIVE server
analyze(data_inputs, callback=None, options=None)
Perform a workflow analysis
-
Parameters
-
data_inputs (
List[WorkflowDataRequest]) – a list of data inputs created using the package_audio(), package_text(), package_image(), or package_video() method. -
callback – an optional callback that is invoked with the workflow completes. If not specified this method blocks, returning OliveWorkflowAnalysisResponse when done. Otherwise this method immediately returns and the callback method is invoked when the response is received. The callback method signature requires 3 arguments: requst, result, error_mssage.
-
options (
Optional[str]) – a JSON string of name/value options to include with the analysis request such as ‘{“filter_length”:99, “interpolate”:1.0, “test_name”:”midge”}’
-
-
Return type
OliveWorkflowAnalysisResponse -
Returns
an OliveWorkflowAnalysisResponse
enroll(data_inputs, class_id, job_names, callback=None, options=None)
Submit data for enrollment.
-
Parameters
-
data_inputs (
List[WorkflowDataRequest]) – a list of data inputs created using the package_audio(), package_text(), package_image(), or package_video() method. -
class_id (
str) – the name of the enrollment -
job_names (
List[str]) – a list of job names, where the audio is enrolled with these jobs support enrollment. This value can be None, in which case the data input(s) is enrolled for each job. -
callback – an optional callback that is invoked when the workflow completes. If not specified this method blocks, returning an OliveWorkflowAnalysisResponse when the enrollment completes on the server. Otherwise this method immediately returns and the callback method is invoked when the response is received.
-
options – a dictionary of name/value option pairs to include with the enrollment request
-
-
Returns
unenroll(class_id, job_names, callback=None, options=None)
Submit a class id (speaker name, language name, etc) for un-enrollment.
-
Parameters
-
class_id (
str) – the name of the enrollment class to remove -
job_names (
List[str]) – a list of job names, where the class is to be unenrolled. Jobs must support class modification . This value can be None, in which case the data input(s) is unenrolled for each job (which is likely dangerous). -
callback – an optional callback that is invoked when this workflow action completes. If not specified this method blocks, returning an OliveWorkflowAnalysisResponse when the enrollment completes on the server. Otherwise this method immediately returns and the callback method is invoked when the response is received.
-
options – a dictionary of name/value option pairs to include with the enrollment request
-
-
Returns
class olivepy.api.olive_async_client.AsyncOliveClient(client_id, address='localhost', request_port=5588, timeout_second=10)
Bases: threading.Thread
This class is used to make asynchronous requests to the OLIVE server
connect(monitor_status=False)
Connect this client to the server
-
Parameters
monitor_server – if true, starts a thread to monitor the server status connection for heartbeat messages
add_heartbeat_listener(heartbeat_callback)
Register a callback function to be notified when a heartbeat is received from the OLIVE server
-
Parameters
heartbeat_callback (
Callable[[Heartbeat],None]) – The callback method that is notified each time a heartbeat message is received from the OLIVE server
clear_heartbeat_listeners()
Remove all heartbeat listeners
enqueue_request(message, callback, wrapper=None)
Add a message request to the outbound queue
-
Parameters
-
message – the request message to send
-
callback – this is called when response message is received from the server
-
wrapper – the message wrapper
-
sync_request(message, wrapper=None)
Send a request to the OLIVE server, but wait for a response from the server
-
Parameters
message – the request message to send to the OLIVE server
-
Returns
the response from the server
run()
Starts the thread to handle async messages
disconnect()
Closes the connection to the OLIVE server
is_connected()
Status of the connection to the OLIVE server
-
Returns
True if connected
classmethod setup_multithreading()
This function is only needed for multithreaded programs. For those programs, you must call this function from the main thread, so it can properly set up your signals so that control-C will work properly to exit your program.
request_plugins(callback=None)
Used to make a PluginDirectoryRequest
-
Parameters
callback (
Optional[Callable[[OliveServerResponse],None]]) – optional method called when the OLIVE server returns a response to this request. If a callback is not provided, this call blocks until a response is received from the OLIVE server. The callback method accepts one argument: OliveServerResponse -
Returns
a OliveServerResponse containing information about available plugin/domains (PluginDirectoryResult)
get_update_status(plugin, domain, callback=None)
Used to make a GetUpdateStatusRequest
-
Parameters
callback (
Optional[Callable[[OliveServerResponse],None]]) – optional method called when the OLIVE server returns a response to this request. If a callback is not provided, this call blocks until a response is received from the OLIVE server. The callback method accepts one argument: OliveServerResponse -
Returns
a OliveServerResponse containing the update status of the requested plugin/domain (GetUpdateStatusResult
load_plugin_domain(plugin, domain, callback)
Used to make a request to pre-load a plugin/domain (via a LoadPluginDomainRequest messge) :plugin: the name of the plugin to pre-load :domain: the name of hte domain to pre-load :param callback: optional method called when the OLIVE server returns a response to this request. If a callback is not provided, this call blocks until a response is received from the OLIVE server. The callback method accepts one argument: OliveServerResponse
-
Returns
a OliveServerResponse containing the update status of the request (LoadPluginDomainResult)
unload_plugin_domain(plugin, domain, callback)
Used to make a unload plugin/domain request (RemovePluginDomainRequest). This request will un-load a loaded plugin from server memory)
-
Plugin
the name of the plugin to unload
-
Domain
the name of hte domain to unload
-
Parameters
callback – optional method called when the OLIVE server returns a response to this request. If a callback is not provided, this call blocks until a response is received from the OLIVE server. The callback method accepts one argument: OliveServerResponse
-
Returns
a OliveServerResponse containing the status of the request (RemovePluginDomainResult)
update_plugin_domain(plugin, domain, metadata, callback)
Used to make a ApplyUpdateRequest
plugin: the name of the plugin to update :domain: the name of hte domain to update :param callback: optional method called when the OLIVE server returns a response to this request. If a callback is not provided, this call blocks until a response is received from the OLIVE server. The callback method accepts one argument: OliveServerResponse
-
Returns
a OliveServerResponse containing the status of the request (ApplyUpdateResult)
get_active(callback)
Used to make a GetActiveRequest
-
Parameters
callback – optional method called when the OLIVE server returns a response to this request. If a callback is not provided, this call blocks until a response is received from the OLIVE server. The callback method accepts one argument: OliveServerResponse
-
Returns
a OliveServerResponse containing the status of the request (GetActiveResult)
get_status(callback=None)
Used to make a GetStatusRequest and receive a GetStatusResult
-
Parameters
callback (
Optional[Callable[[OliveServerResponse],None]]) – optional method called when the OLIVE server returns a response to the request. If a callback is not provided, this call blocks until a response is received from the OLIVE server. The callback method accepts one argument: OliveServerResponse -
Returns
a OliveServerResponse that contains the most recent server status (GetStatusResult)
analyze_frames(plugin, domain, audio_input, callback, mode=, opts=None)
Request a analysis of ‘filename’, returning frame scores.
-
Parameters
-
plugin – the name of the plugin
-
domain – the name of the plugin domain
-
audio_input – the audio to score
-
callback – optional method called when the OLIVE server returns a response to this request. If a callback is not provided, this call blocks until a response is received from the OLIVE server. The callback method accepts one argument: OliveServerResponse
-
mode – the audio transfer mode
-
opts – a dictionary of name/value pair options for this plugin request
-
-
Returns
a OliveServerResponse containing the status of the request (FrameScorerResult)
analyze_regions(plugin, domain, filename, callback, mode=)
Request a analysis of ‘filename’, returning regions
-
Parameters
-
plugin – the name of the plugin
-
domain – the name of the plugin domain
-
filename – the name of the audio file to score
-
callback – optional method called when the OLIVE server returns a response to the request. If a callback is not provided, this call blocks until a response is received from the OLIVE server. The callback method accepts one argument: OliveServerResponse
-
mode – the audio transfer mode
-
-
Returns
a OliveServerResponse containing the status of the request (RegionScorerResult)
analyze_global(plugin, domain, audio_input, callback, mode=)
Request a global score analysis of ‘filename’
-
Parameters
-
plugin – the name of the plugin
-
domain – the name of the plugin domain
-
audio_input – the name of the audio file to score
-
callback – optional method called when the OLIVE server returns a response to the request. If a callback is not provided, this call blocks until a response is received from the OLIVE server. The callback method accepts one argument: OliveServerResponse
-
mode – the audio transfer mode
-
-
Returns
a OliveServerResponse containing the status of the request (GlobalScorerResult)
enroll(plugin, domain, class_id, audio_input, callback, mode=)
Request a enrollment of ‘audio’
-
Parameters
-
plugin – the name of the plugin
-
domain – the name of the plugin domain
-
class_id – the name of the class (i.e. speaker) to enroll
-
audio_input – the Audio message to add as an enrollment addition
-
callback – optional method called when the OLIVE server returns a response to the request. If a callback is not provided, this call blocks until a response is received from the OLIVE server. The callback method accepts one argument: OliveServerResponse
-
mode – the audio transfer mode
-
-
Returns
a OliveServerResponse containing the status of the request (ClassModificationResult)
unenroll(plugin, domain, class_id, callback)
Unenroll class_id
-
Parameters
-
plugin – the name of the plugin
-
domain – the name of the plugin domain
-
class_id – the name of the class (i.e. speaker) to remove
-
callback – optional method called when the OLIVE server returns a response to the request. If a callback is not provided, this call blocks until a response is received from the OLIVE server. The callback method accepts one argument: OliveServerResponse
-
-
Returns
a OliveServerResponse containing the status of the request (ClassRemovalResult)
audio_modification(plugin, domain, audio_input, callback, mode=)
Used to make a AudioModificationRequest (enhancement).
-
Parameters
-
plugin – the name of the plugin
-
domain – the name of the plugin domain
-
audio_input – the audio path or buffer to submit for modification
-
callback – optional method called when the OLIVE server returns a response to the request. If a callback is not provided, this call blocks until a response is received from the OLIVE server. The callback method accepts one argument: OliveServerResponse
-
mode – the audio transfer mode
-
-
Returns
a OliveServerResponse containing the status of the request (AudioModificationResult)